
Data Access, Integration, Sharing, and Interoperability Issues
Conventional Approaches and EIQ Product's Approach to Data Issues
Federated Data Systems with Conventional Adapters
The advantages and disadvantages of federated data systems with conventional adapters:
Federated Data Systems Using EIQ Products
The advantages and disadvantages of federated data systems with EIQ Product adapters:
EIQ Product Suite Components Overview
EIQ Product Server (also referred to as EIQ Server)
EIQ DSTransMon Configuration Tool
This document provides an overview of the SmartData Fabric® EIQ Product Suite and its components along with the concepts behind the EIQ approach. This document covers the following topics:
WhamTech External Index and Query (EIQ) Products™ solve most data access, integration, sharing, and interoperability challenges faced by organizations in an innovative and unique way.
EIQ Products combine technologies from the conventional approaches of data warehousing, federated adapters, and enterprise search. EIQ Products use a hybrid approach to retain most of the advantages of the conventional approaches while overcoming most of the disadvantages.
EIQ Products provide client applications access to multiple, disparate, and distributed data sources - including those containing structured, unstructured, and semi-structured data. In a typical edge-ware configuration, EIQ Product servers act similarly to conventional data adapters in federated query systems. However, there is a key difference. EIQ Product servers provide enhanced query capabilities by using their own dataless indexes (EIQ Indexes) for processing Structured Query Language (SQL) queries and going to data sources only for the results data. EIQ Product tools read data from data sources and put the data through cleansing, transformation, and standardization processes to build dataless indexes while leaving data in its original form. EIQ Product tools also maintain the indexes to reflect changes to data sources in near-real-time to provide access to up-to-date information. EIQ Product tools put the results data through the same data quality processes as indexes, merge multiple data source results, and provide the results to calling applications or middleware.
Queries against EIQ Indexes are highly successful because of their clean and standardized nature. EIQ Products also absorb the query processing load from the data source system making queries much faster. Additional indexes for actions like fuzzy matching can provide querying capabilities that are otherwise not available from the data source.
It is important to note that EIQ Indexes are dataless. They do not retain data locally but hold pointers to data in data sources. Regular database management systems, including data warehouses, retain a copy of the data locally along with index trees and record number lists. However, EIQ Indexes use 'virtual indexes' containing only the index trees and the corresponding record number lists - not the data. EIQ Products go directly to the data sources to access the raw record data results when necessary.
EIQ Products connect to data sources through available drivers/APIs and query languages. Clients connect to EIQ Product servers through standard database access drivers (ODBC, JDBC, OLEDB) and Web Services using SQL.
The problem with data that most organizations face is that they are awash with it and it is rarely available in a usable form for other purposes. In many cases, the hurdles to data access, integration, sharing, and interoperability are more than technical and are related to culture, security, and privacy. WhamTech's EIQ Product Suite helps alleviate these hurdles. EIQ Products combine technologies from the conventional approaches of data warehousing, federated adapters, and enterprise search. EIQ Products power the best-of-all-worlds solutions by leaving data where it is and providing query-able metadata layers that work with original data sources, data source schemas, and formats. Unlike other approaches, EIQ Products address all of the data issues listed above.
EIQ Products provide the real alternative to conventional approaches for data access, integration, sharing, and interoperability across multiple, disparate data sources with higher success and lower complexity, implementation time, and cost. This provides real value for business intelligence (BI), analytics, marketing, customer data integration (CDI), master data management (MDM), and other data-centric solutions.
The following sections describe the conventional and WhamTech EIQ Product approaches.
Data is extracted from multiple data sources, transformed, and loaded (ETL) into a separate database called a data warehouse.
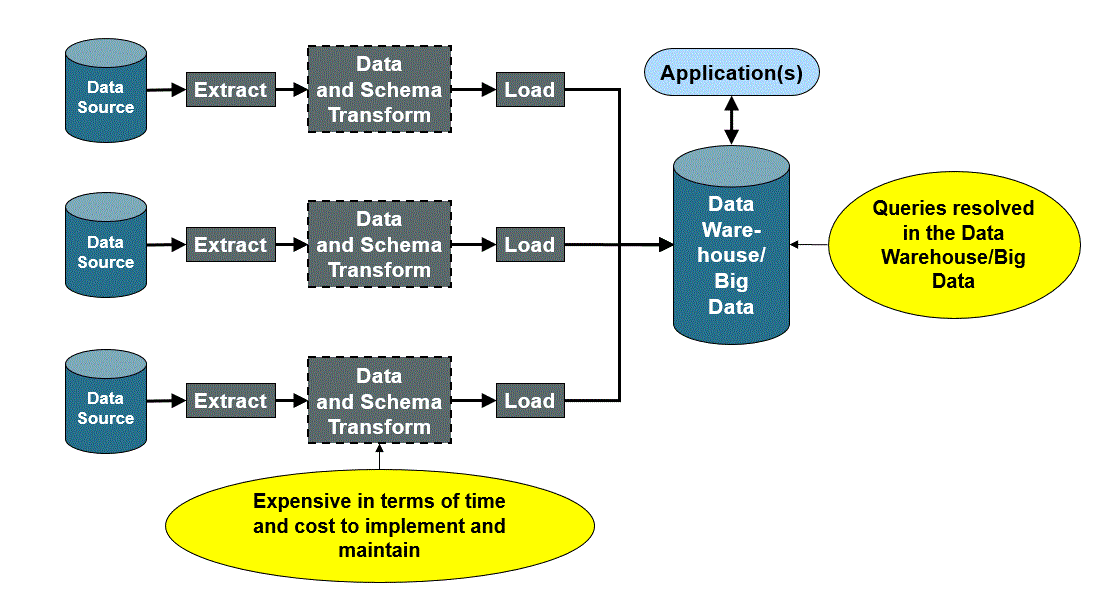
Figure 1: Data Warehousing
The advantages and disadvantages of data warehouses:
Advantages:
Data warehouses tend to have a high query success as they allow complete control over data once copied:
· High query success
o Data is clean and usable
o Multiple and consistent indexes across data
o Complete control over query processing
· No load on, or interference with, data source systems
· High performance
· Allows for pre-aggregated and pre-calculated fields
· Good for archival purposes
· Can provide access security - row, column (and data element) based access
· Original data sources will not be aware of queries
Disadvantages:
However, there are considerable disadvantages involved in moving data from multiple and often highly disparate data sources to a single data warehouse, such as long implementation time, high cost, lack of flexibility, dated information, and limited capabilities:
· Major data schema transforms from individual data sources into one schema in the data warehouse. This can represent more than 50% of the total data warehouse implementation effort.
· Data owners lose control over their data, raising issues on responsibility, accountability, security, and privacy.
· Long initial implementation time and associated high cost
· Adding new data sources takes time and associated high cost.
· Has limited flexibility on use and users requiring multiple separate data marts for multiple uses and types of users
· Data is typically static and dated, and changes in data cannot be actively monitored
· Does not usually support data drill-down capabilities
· Difficult to accommodate changes in data types and ranges, data source schema, indexes, and queries
· Complete additional system cost including storage
In federated systems using conventional adapters, data remains in data sources and queries are translated from a common data model to queries that each data source can execute. Queries executed on data source systems and the results are retrieved. The components that translate queries and transform result-sets are called adapters.
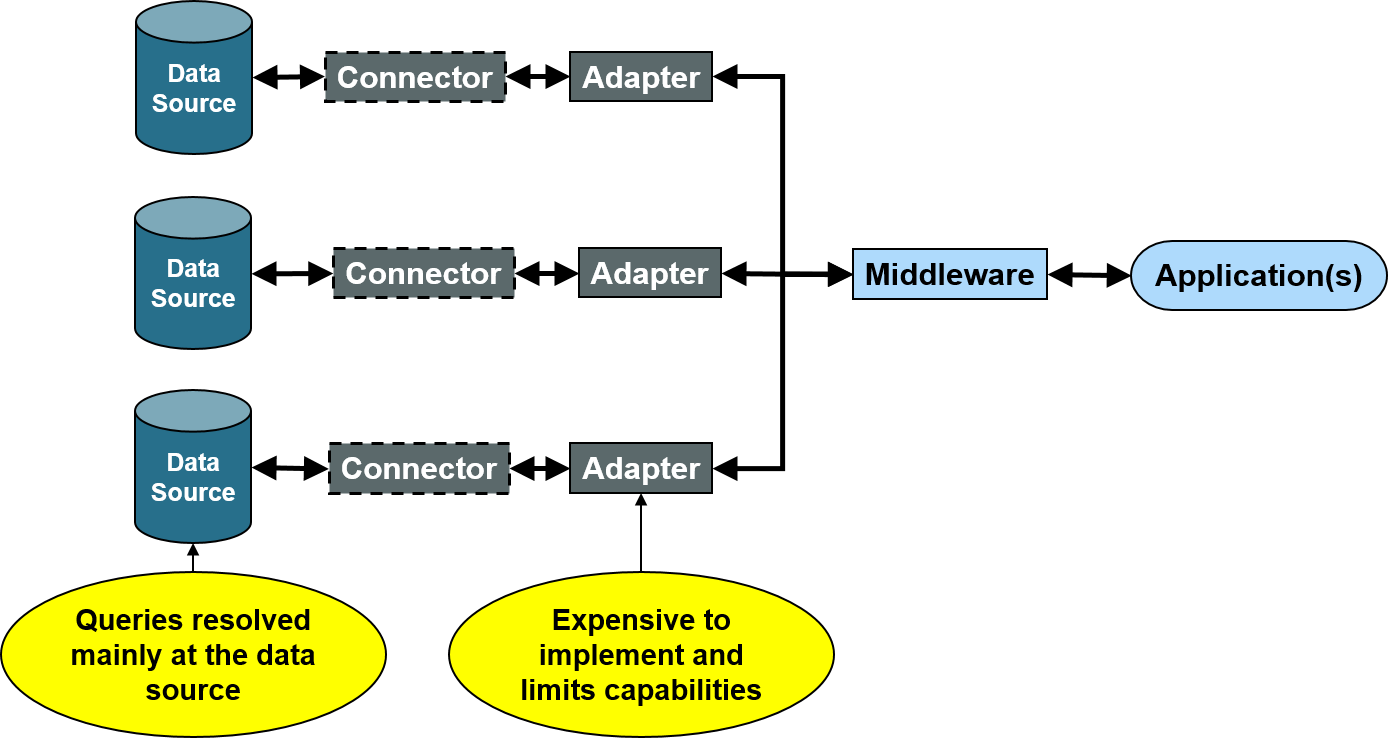
Figure 2: Federated Data System with Conventional Adapters
Advantages:
Federated data systems with conventional adapters were pursued in an attempt to overcome some of the disadvantages of data warehouses by providing the following primary benefits:
§ Lengthy, costly, and complex ETL process*
§ Data ownership issues
§ Static and dated data
§ Lack of drill-down capabilities
· Little or no additional storage required
Disadvantages:
However, there are considerable disadvantages using federated data systems with conventional adapters due to data source constraints:
· Low query success
· Data is not clean and is sometimes unusable.
· Limited indexes are inconsistent across data sources and are inflexible.
· Limited query processing
· Query load is placed on data source system.
· Query performance can be an issue.
· Queries are "hard-wired".
· Federated systems cannot actively monitor data sources.
· It's expensive and time-intensive to develop adapters.
· No pre-aggregated or pre-calculated fields
· Data sources aware of queries
· No archive
· No results if data source is unavailable.
To accommodate the translation between an application or information sharing system and any particular data source, conventional adapters are developed over a significant period and at great cost to cover basic requirements. In fact, it usually costs 300 to 500% more than the initial adapter purchase to customize conventional adapters that cover basic requirements.
*The only advantage conventional adapters have over the ETL process is that schema transforms become less difficult; however, query processing and subsequent result transforms become more complex.
EIQ Products combine the conventional approaches of data warehousing, federated adapters, and enterprise search to retain the majority of the advantages while overcoming most of the disadvantages. EIQ SuperAdapter and EIQ TurboAdapter configurations replace conventional adapters in federated data systems to bring many benefits of data warehousing to federated data systems. EIQ Products add clean, standardized, and enhanced indexes to absorb query processing from data sources.
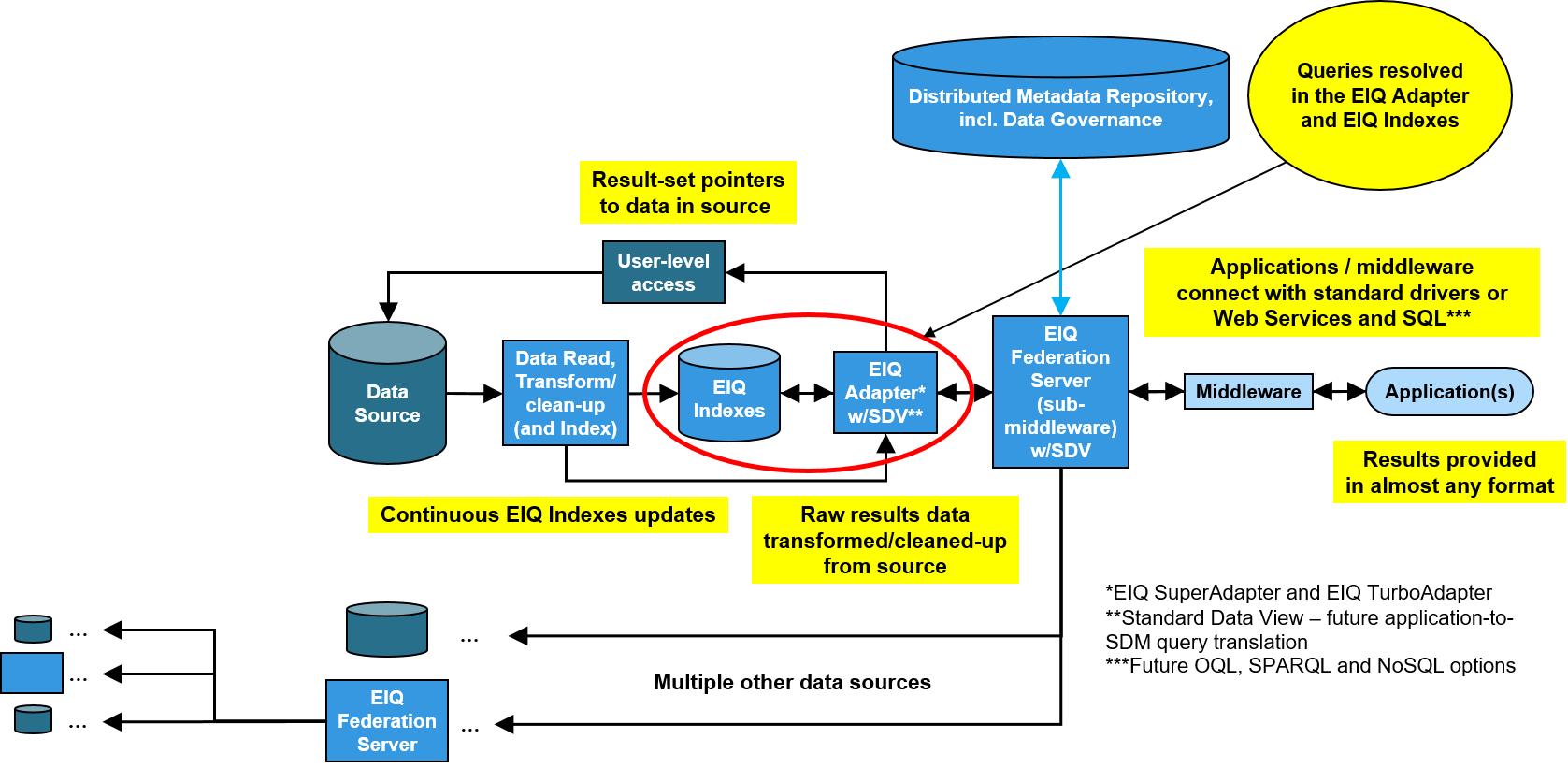
Figure 3: Federated Data System with EIQ Products
Depending on the configuration, EIQ Product servers function either as adapters (EIQ SuperAdapter, EIQ TurboAdapter, and EIQ ConventionalAdapter - collectively referred to as EIQ Edgeware) or as federation servers (EIQ Federation Server). When configured as EIQ Edgeware - with a single instance dedicated per data source - EIQ Product servers provide access to a single data source. An EIQ Federation Server connects multiple EIQ Edgeware servers to provide access to multiple data sources through a single common interface based on a standard data model.
For details on various EIQ Product server configurations, refer to the EIQ Product Server Introduction.
The EIQ SuperAdapter and EIQ TurboAdapter configurations execute queries at EIQ Indexes. Two features of EIQ Indexes are important to note:
1) Unlike in data warehousing, EIQ Indexes are built according to the schema defined in the data source. They require no schema transformations
2) EIQ Indexes primarily use 'virtual indexes' containing only index trees and the corresponding record number lists. No actual data is used. The only exceptions are ROWID columns and other columns indicated as foreign keys. These are designated as Non-virtual keys.
EIQ Indexes may contain two types of indexes: Content Indexes and Link Indexes. Content Indexes are for content derived from data sources, whereas Link Indexes are formed to link records from within and across data sources based on specific link criteria. Only EIQ SuperAdapters can form link indexes. Link Indexes are discussed in detail under the Link Indexes section.
In a typical content index, each index table has a column designated as a ROWID column. This ROWID column must contain only unique values; that is, each value in this column uniquely identifies a single row in that table. Usually the Primary Key column in a table is designated as a ROWID column. The ROWID column values are used for retrieving raw results data for matching rows from the data source as needed. If there is no single primary key column for a table, then multiple columns that form unique value can collectively be designated as ROWID columns.
It is necessary to keep EIQ Indexes in sync with data in the corresponding data source to obtain up-to-date results. If the values in the data source are modified, indexes need to be maintained by updating them with new values. There are multiple options available for updating EIQ Indexes.
With EIQ SuperAdapters and EIQ TurboAdapters, queries are resolved almost 100% at the EIQ Indexes providing the following benefits:
Advantages:
· High query success because indexes/results data are clean and usable.
· Indexes are consistent across disparate data sources.
· Complete control over query processing at EIQ Indexes
· Data remains at the source.
· Latest data is available
· Almost no index or query load on data source systems
· No major schema transforms.
· EIQ Products can actively monitor indexes and data sources and send notifications when complex events happen
· Rapid query response
· Additional indexes
o De-normalized indexes
o Indexed views/aggregate indexes
· Additional query capabilities
o Text Search
o Entity Extraction
o Information geometry tool
o Fuzzy matching
o Link Indexes™ for performance and link analysis
· Highly flexible
· Provide row, column (and data element) security indexes
· User-level access to data sources
· Return results from indexes even if data sources become unavailable.
· Data sources only aware of low-level results requests; not the full queries.
Apart from these advantages, EIQ Products also help alleviate cultural hurdles for implementing data access and information sharing solutions across organizations.
Disadvantages:
Table 1: Comparison between EIQ Products and other approaches ranked by advantage to EIQ Products:
|
Number |
Features |
EIQ Products |
Data Warehouses |
Federated Systems with Conventional Adapters |
Comments |
|
1 |
Minimal implementation time |
|
|
|
Advantages are unique to EIQ Products. |
|
2 |
Quickly add new data sources |
|
|
|
|
|
3 |
Flexibility of use and users |
|
|
|
|
|
4 |
Actively monitor data sources |
|
|
|
|
|
5 |
Full text search |
|
|
|
|
|
6 |
Unlimited query options and performance |
|
|
|
|
|
7 |
De-normalized views |
|
|
|
|
|
8 |
Link mapping and analysis/data mapping |
|
|
|
|
|
9 |
No major schema transforms |
|
|
|
|
|
10 |
Can write to data sources |
|
|
|
|
|
11 |
Row, column, and data element security |
|
|
|
|
|
12 |
Data source changes readily made |
|
|
|
|
|
13 |
Clean and usable data |
|
|
|
|
|
14 |
Consistent and multiple indexes and types |
|
|
|
|
|
15 |
Almost any data source |
|
|
|
|
|
16 |
Do not install anything on data source systems |
|
|
|
|
|
17 |
Pre-aggregated and pre-calculated fields |
|
|
|
|
|
18 |
Results when data sources are unavailable |
|
|
|
|
|
19 |
Data remains at source |
|
|
|
|
|
20 |
User-level access to data sources |
|
|
|
|
|
21 |
Latest data available |
|
|
|
|
|
22 |
Drill-down capabilities |
|
|
|
|
|
23 |
No index or query load on data source systems |
|
|
|
Data warehouses provide these advantages over EIQ Products and federated systems with conventional adapters. |
|
24 |
Data source owners are not aware of queries |
|
|
|
|
|
25 |
Archive |
|
|
|
|
|
26 |
Good for standard application data sources |
|
|
|
|
|
27 |
No need for data or index update process |
|
|
|
|
|
28 |
No additional system cost |
|
|
|
[1] Real-time data warehouses only
[2] Data warehouses, typically, do not have full text
search
[3] Additional databases or data marts, typically, are
used for unlimited query options and performance
[4] Additional databases or data marts, typically, are
used for de-normalized views
[5] Additional databases or data marts, typically, are
used for link analysis/data mining
[6] No major schema transform if flat front-end schema
is used, e.g., GJDXDM and NIEM in government
[7] Data owners relinquish control over their data. Only
one or two DBMS vendors provide this level of security
[8] Only if data sources provide this level of security (see
footnote 7)
[9] EIQ Products can accommodate some changes, for instance,
indexes can be used to create new indexes; however, fundamental changes may
require individual column re-indexing.
[10] Federated systems with conventional adapters can
accommodate minor changes, but not to the extent that EIQ Products can.
[11] Many federated systems with conventional adapters require
specialized connectors and/or special access that requires installation of
something on data source systems.
[12] Only for real-time or active data warehouses
[13] Can be implemented in data warehouses, but not typically.
[14] Small overhead on data source system when retrieving final
result-set data
[15] Data source system receives low-level requests for
specific records only - not the query that resulted in them.
[16] EIQ Products can store results data; work with mirror-image
copies of original data sources that act as archives, complying with
Sarbanes-Oxley and other regulations (data warehouses are not considered
original data source copies); and maintain an index to archive.
[17] Can use application vendor or third-party change data
capture (CDC) capability or results level indexes.
[18] Only index update process, but not data
[19] EIQ Products, typically, have separate servers for
query processing and storage for indexes, but not storage for data or separate
DBMS to maintain like in data warehouses.
[20] Federated systems with conventional adapters, typically,
have separate servers and require minimal storage.
EIQ Product Suite package comes with a set of servers, client and administrative tools, connectors and access drivers, and software development kits (SDK). Refer to Figure 4 below for an overview of the EIQ Product internal architecture and components.
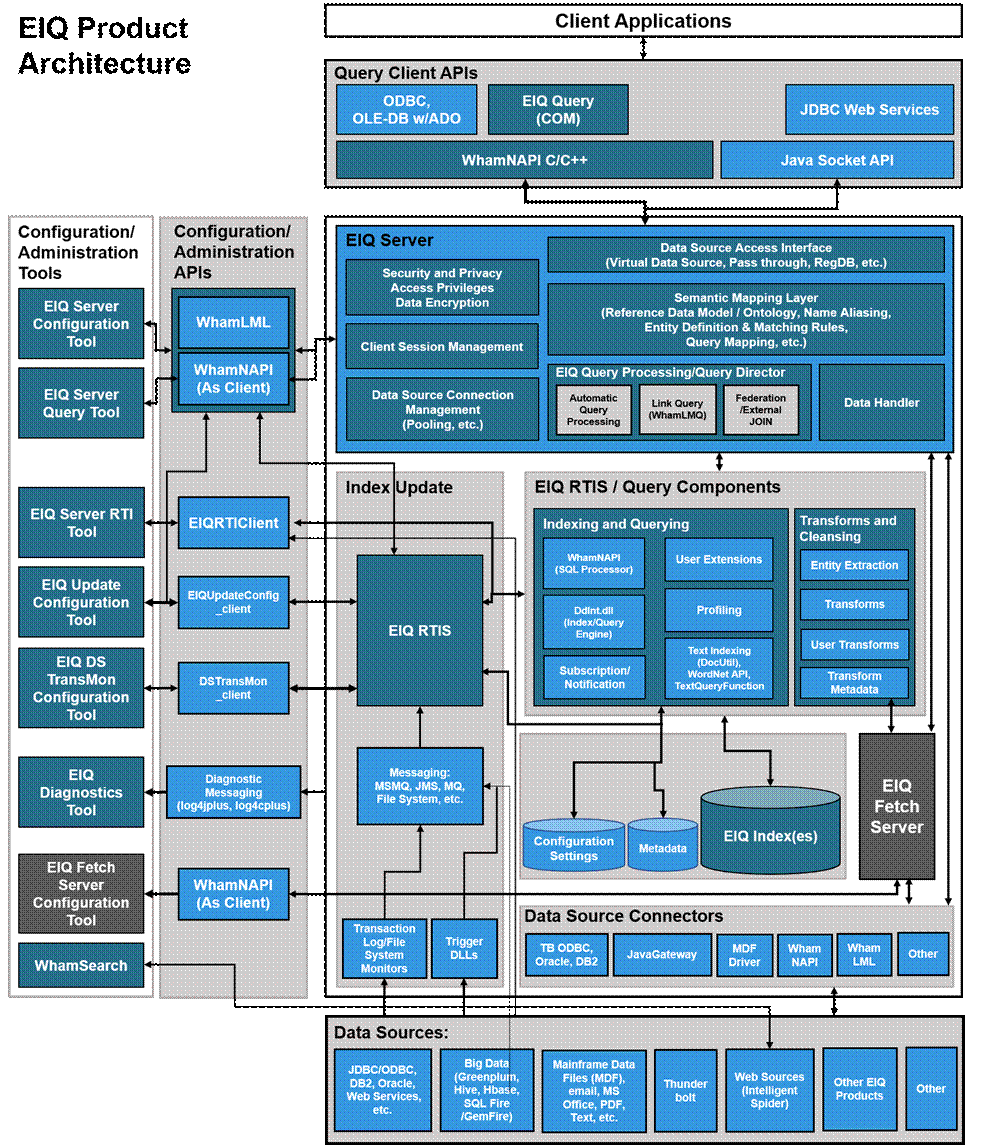
Figure 4: EIQ Product Architecture and Components
EIQ Server and EIQ RTIS are the main server components included in the suite.
EIQ Server is the central component that provides data access, integration, sharing, and interoperability services. EIQ Server can be deployed in multiple configurations depending on product licensing and desired functionality. These configurations include EIQ SuperAdapter, EIQ TurboAdapter, EIQ ConventionalAdapter, and EIQ Federation Server.
EIQ RTIS helps keep EIQ Indexes in sync with changes in corresponding data sources by monitoring transaction, change and redo logs, and then applying the appropriate changes where necessary.
For details on these servers, refer to the following links:
The administration tools included in the EIQ Product Suite provide a user-friendly interface that simplifies the server configuration process. The EIQ Server RTI Tool is used to build the initial EIQ Indexes. The EIQ Server Configuration Tool is used to configure the EIQ Server as a specific EIQ Product server configuration. The EIQ Update Configuration Tool is used to configure EIQ RTIS.
A client query tool and a diagnostic tool are also included. For details on each tool, refer to the following links:
EIQ DS TransMon Configuration Tool
JavaGateway with WhamEE - an Entity Extraction server that extracts entities out of text.
WhamSearch - an Intelligent web spider that finds documents matching given criteria based on relevant keywords, watch lists or Information Geometry models.
Various data source connectors and drivers are supplied for connecting to databases, such as, Oracle, Microsoft SQL Server, Teradata, DB2, and Mainframe data files.
The EIQ Product Suite comes with ODBC, OLEDB, and JDBC drivers to help clients connect with EIQ Product servers. Clients can also use a Web Services interface for connection.
The EIQ Server is the key component of the EIQ Product Suite. The EIQ Server can be deployed in multiple configurations depending on product licensing and desired functionality. These configurations include EIQ SuperAdapter, EIQ TurboAdapter, EIQ ConventionalAdapter, and EIQ Federation Server. These configurations and the concepts behind the configurations are described in the EIQ Product Server Introduction.
The EIQ Server Configuration Tool is used for configuring and managing EIQ Product servers. EIQ Product servers run as services and they must be running before query clients can connect.
This tool helps admins to:
EIQ RTIS keeps EIQ Indexes in sync with changes in corresponding data sources. EIQ RTIS communicates with the data sources through a messaging system. The message system holds any update notification messages from data sources for EIQ RTIS. It is also capable of monitoring message queues such as MSMQ and JMS and can be used in place of database triggers.
On the data source side, the admin must set some form of change recognition and notification mechanism that uses transaction logs, change logs, replication, etc., and send any updates to the message system as messages. EIQ RTIS actively polls the message system and applies updates to EIQ Indexes in near-real-time.
For a detailed description of the index update process and tools, see EIQ Server Update Process.
EIQ RTIS is configured using the EIQ Update Configuration Tool and EIQ DS TransMon Configuration Tool.
The EIQ Update Configuration Tool is used to configure EIQ RTIS and provide an interface for administering and monitoring it. The EIQ Update Configuration Tool enables admins to create update tasks associated with data sources and their EIQ indexes. Admins can assign EIQ RTIS to a message queue and set the polling interval.
In addition, a mechanism to start and stop the services that monitor the notifications sent via the message system is provided.
The EIQ DS TransMon Configuration Tool is also used to configure EIQ RTIS and provide an interface for administering and monitoring it. This tool enables administrators to create tasks associated with data sources and task items associated with EIQ Server Virtual Data Sources. Administrators can assign a message queue to each task item.
In addition, a mechanism to start and stop the task items that monitor the data sources is provided.
The EIQ Server RTI Tool is used to create the initial EIQ Indexes for data sources. Users can perform various functions including data type mappings, transforms, and relational key settings (Primary Key/Foreign Key). This tool also lets users build indexed views and text search indexes with various options, build and view data profiles, and try various transforms.
EIQ Server RTI Tool generates map files containing EIQ Index definitions that can be edited for future modifications.
WhamTech JavaGateway serves as a gateway to EIQ Product components for accessing data sources that support only Java APIs (JDBC, Java APIs).
The EIQ Server Query Tool is a client application that provides a graphical user interface to:
The EIQ Server Query Tool provides quick access to recently executed queries, detailed query execution paths that allow admins to easily track data flow in complex EIQ setups, and a results set grid for easy viewing.
The EIQ Server Query Tool also provides a mechanism for admins to open and check EIQ Indexes directly.
The EIQ Diagnostics Tool provides message tracing and logging for troubleshooting the EIQ Product Suite components through a simple user-friendly interface.
Copyright © 2019 , WhamTech, Inc. All rights reserved. This
document is provided for information purposes only and the contents hereof are
subject to change without notice. Names may be
trademarks of their respective owners.