
WhamSearch Intelligent Spider User Guide
Intelligent Spider System Configuration
Spidering, Initializing and Using Web Content Indexes
Step 1: Spider the domain URLs
Step 2: Build Initial Web Content Indexes
Step 3: Register Web Content Index with the EIQ Server as Data Source
Step 4: EIQ RTIS Configuration
This guide describes the functionality of the WhamSearch Intelligent Spider and provides instructions on how to configure the tools to work with it.
WhamSearch and EIQ Product tools combine to help data analysts find relevant content on the web through advanced intelligent spidering directed by relevant keywords, watch lists, and information geometry models (find similar documents). Analysts can automatically extract entities out of the content (structured data out of unstructured text), combine web content with other sources of data through the EIQ Federation Server, and get real-time alerts when the intelligent spider encounters material of interest.
Note: If the WhamSearch Intelligent Spider is not included in the EIQ Product Suite Installation Media, contact WhamTech at devsupport@whamtech.com.
WhamSearch: WhamSearch is an intelligent spider that finds relevant content from the web meeting user-defined criteria (based on keywords, watch lists, and information geometry based models). The output from WhamSearch is processed by other tools to provide text search and complex event processing.
JavaGateway configured as WhamEE: WhamEE (WhamTech Entity Extraction) identifies and extracts entities out of WhamSearch generated web content using third party, open source, GATE software. WhamEE passes the extracted entities, along with the original web content, to EIQ RTIS.
EIQ RTIS: EIQ RTIS monitors the output from WhamEE and passes new content to the EIQ Server to update web content search indexes in near-real-time. The new web content is immediately available for querying by clients.
EIQ Server: EIQ Server provides a SQL query interface to client applications. The clients connect to EIQ Server to query the indexes for WhamSearch generated web content.
EIQ Server RTI Tool: The EIQ Server RTI Tool helps admins initialize empty web content indexes. It provides users with options to build various types of indexes including word stems, synonyms, SOUNDEX, Metaphone, and Proximity. It also includes options to build indexes that consider word weighting.
This guide assumes the WhamSearch systems have the following configuration:
· Microsoft Windows 2003 or 2008 Server with the latest service packs for medium scale deployments
· Microsoft Windows XP with latest service packs for Developer/Trail versions/Small scale deployments
· High-speed Internet access
For performance and scalability, the following system configuration is strongly recommended:
WhamSearch takes the initial domain URLs (given in a CSV file), crawls the web to find relevant documents, and writes content bucket files to a specified output directory.
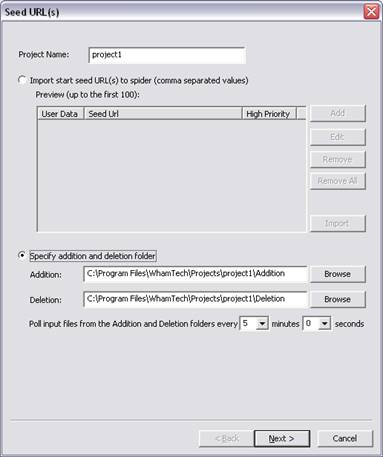
a. If you want to import the Seed URL(s) from a file:
Select the first radio button and click "Import" to import a comma separated value file (.CSV or .TXT) that contains the Seed URLs.
b. You can set the spider to continuously monitor two folders for seed URLs; one folder for adding seed URLs to the index or to re-spider existing URLs and the other for deleting specified seed URLs and the crawled child-URLs from the index:
Select the second radio button and Browse for the folders you want to specify for Addition and Deletion. You can also specify the polling interval time in minutes and seconds.
Click "Next".
Seed URLs File Format: Note that the file that has the seed URLs has to be a comma-separated values file (either .CSV or .TXT). The format for specifying a seed URL is "userdata, seedURL, priority", where userdata is generally some form of ID field. For example, "account ID" - seedURL is the starting URL that will be spidered. It must begin with "http://" - and priority is a single-character optional flag where 'Y' denotes high priority and 'N' denotes normal priority. URLs with priority 'Y' will be spidered the moment they are submitted, even if other normal-priority URLs are being processed currently.
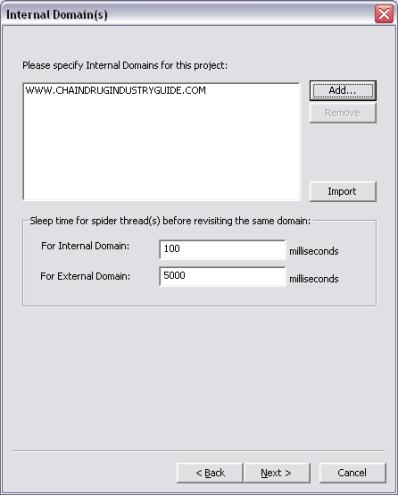
Note: The distinction in thread sleep times for internal and external domains significantly improves spidering speed. Also, specifying internal domains is an optional step.

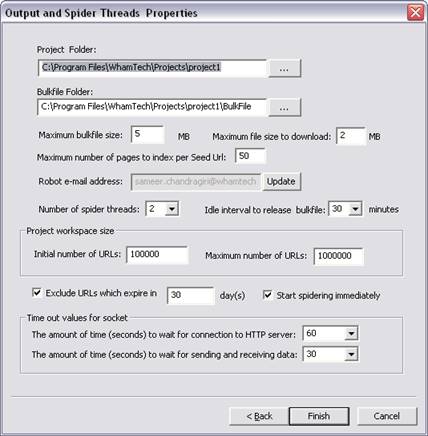
At the end of spidering the current set of URLs, the "URLs in the queue" section in the status bar at the bottom displays 0 (zero).
Logging: WhamSearch creates a log file and writes the names of any failed URLs and the reason for failure. The log file is located in the "C:\Program Files\WhamTech\Log" folder. "C:\Program Files\WhamTech" is the WhamSearch Installation folder.
Adding additional Seed URLs while Spider is running: WhamSearch spiders the domains in the order given in the input file. Once spidering starts, users can add new domains that have not been previously spidered by right-clicking "Start Seed URL(s)" for the relevant project in the left pane. Users can set a high-priority flag to domains by selecting the "high-priority" checkbox. These domains will be spidered almost immediately and will be available for EIQ RTIS to update the indexes. Users can also add new domains or re-spider previously spidered domains by placing a new seed URL CSV file in the "Addition" folder. This is available if the ‘folders’ option was chosen while creating the project.
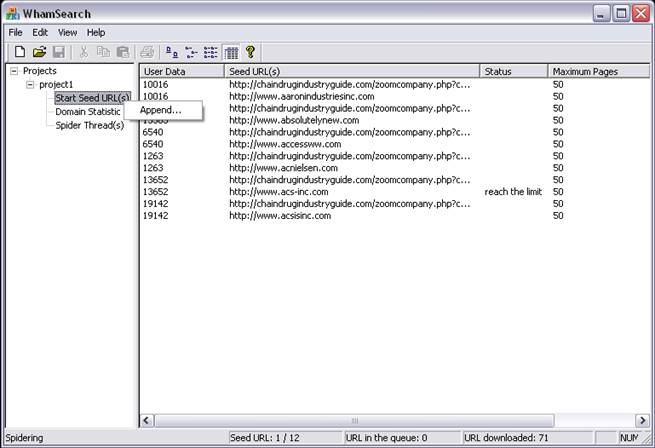
To close the WhamSearch tool while a project is being spidered, or to release the current set of output bulk files that the threads are writing to (without waiting till the "idle interval to release bulkfiles" elapses), the spider threads have to be manually stopped by the user. This can be done by right-clicking "Spider Thread(s)" and selecting "Stop". The spider threads can be started again manually by right-clicking "Spider Thread(s)" and selecting "Start" or automatically by placing a seed URL .CSV (or .TXT) file in the Addition/Deletion folder.
Project settings are saved automatically as an .XML file under the project folder with the name <project_name>.xml.
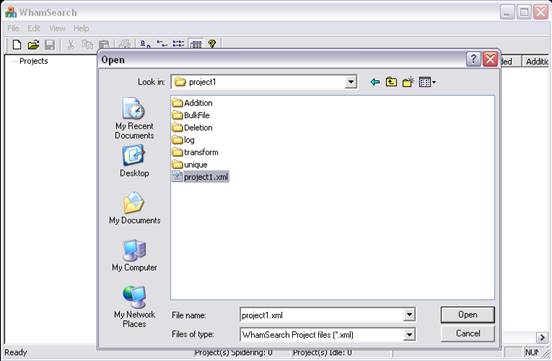
To open a saved project, click "File” and select “Open”. Browse to the relevant XML project file and click "Open". You can also click the “Open” icon on the toolbar.
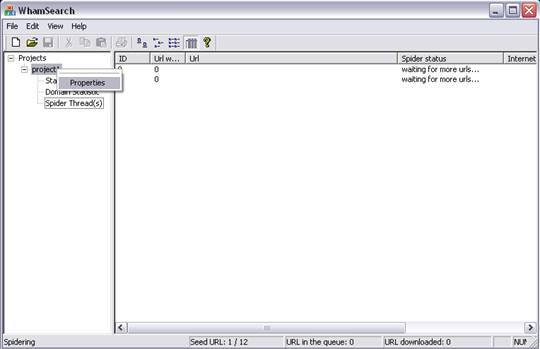
This opens the “Properties” dialog shown below:
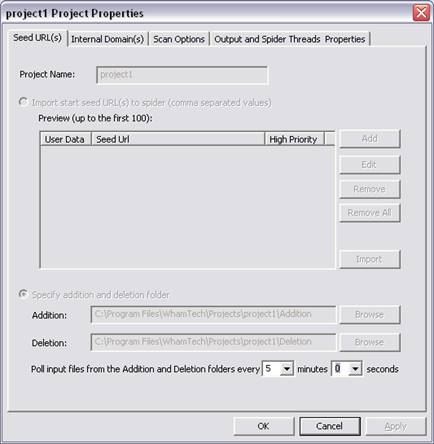
Here, the user can change properties such as the Folder polling interval, scan options, and maximum bulkfile size.
Note: WhamSearch uses the user specified time-out period for sockets before proceeding to the next URL in the queue. If a user stops and re-starts spider threads, WhamSearch retries those timed-out URLs first before processing any other URLs given in the Addition/Deletion folders.
Using the EIQ Server RTI Tool, build initial web content indexes on bucket files from a WhamSearch output directory.
Note: Before using the EIQ Server RTI Tool to build web content indexes on the spidered bulkfiles (.TSI), make sure to stop the spider threads in the WhamSearch tool. This releases the locks on the .TSI files so that index building can proceed properly. You can resume spidering once the index building is completed.
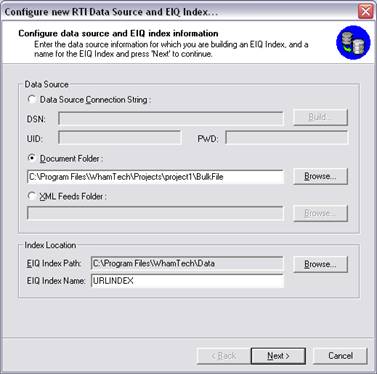
For 'Index Location', enter the path where you wish to store the web content index files, for example, C:\Program Files\WhamTech\Data\URLINDEX. A folder with the name entered in 'EIQ Index Name' is created under the 'EIQ Index Path'.
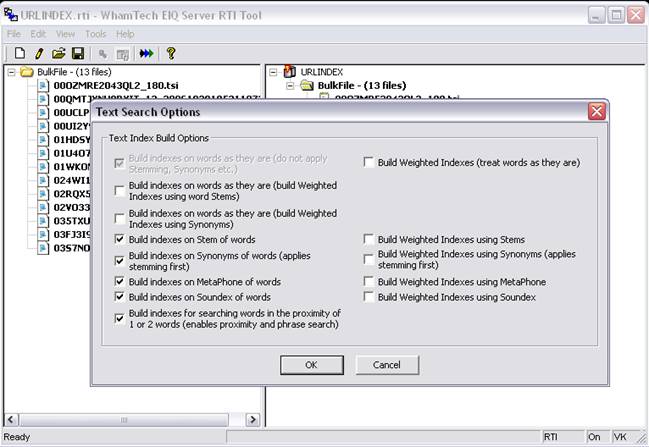
Note: Make sure to check "Build Indexes for searching words in the proximity of 1 or 2 words" to enable phrase search. Without these indexes, WhamSearch cannot find phrases.
DO NOT select weighted indexes; they are not applicable to WhamSearch and might increase indexing time and disk space needed to store the index files.
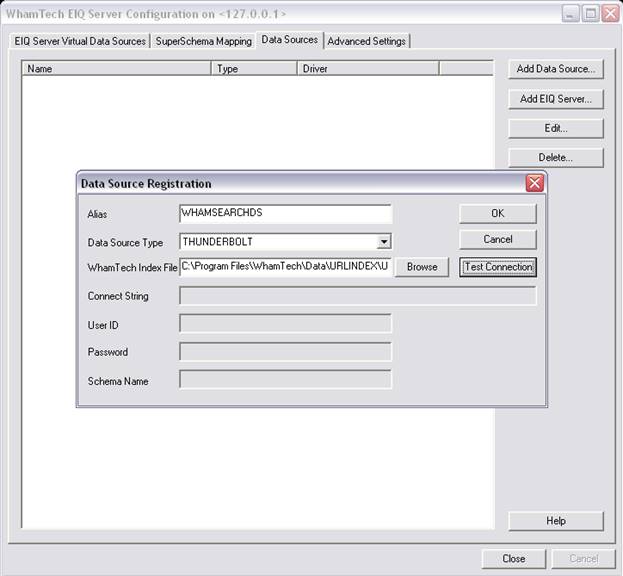
Register the web content index as a data source with the EIQ Server. Make sure that "WhamTech EIQ Server" and "WhamTech EIQ RTIS" are running.
Create a Thunderbolt Data Source associated with the sample web content index using the EIQ Server Configuration Tool by following these steps:
· Go to the 'Data Sources' tab and select 'Add Data Source.'
· In the 'Data Source Registration' window, enter 'WHAMSEARCHDS' as the Alias; 'THUNDERBOLT' as the Data Source Type; and Browse for
'URLINDEX.DBD' as the index file
· Select 'Test Connection' and click ‘OK’.
· Close the EIQ Server Configuration Tool.
Now, you can query the web content indexes using the EIQ Server Query Tool or other client tools using EIQ Server drivers (ODBC, OLEDB, JDBC, and Web Services).
See detailed search syntax here.
Configure EIQ RTIS to poll a WhamSearch or WhamEE output directory for any new files to update the specified web content index in near-real-time.
See EIQ Update Configuration Tool for more information.
See Entity Extraction Help for details regarding WhamEE configuration.
Copyright © 2019 , WhamTech, Inc. All rights reserved. This
document is provided for information purposes only and the contents hereof are
subject to change without notice. Names may be
trademarks of their respective owners.