
MASTER DATA MANAGEMENT IN EIQ PRODUCT SUITE
Build EIQ Adapters for the Data Sources
Setting-Up the Master Data Sources
Creating ODBC Data Source Names (DSN) for the Master Data Sources
Configuring EIQ SuperAdapters for Master Data Sources
Creating VDSs for the EIQ SuperAdapters
Virtual Schema View (SuperSchema) Mapping
Configure Data Federation Across the Adapters
Configure Master Data Matching and Merge Rules to Build Master Data
Map Master Data Columns for Querying and Execute Sample Queries
A major benefit of the EIQ Product Suite is the ability to create and maintain master data from data across multiple data sources in a distributed manner. The EIQ Product Suite does this without making copies of data in a central location while easily and seamlessly integrating master data with operational data without putting a query load on the underlying data sources. This is accomplished by taking advantage of built-in data federation and link indexing features in the EIQ Product Suite.
The master data generation process is based on finding matching attribute values for master data entity attributes. Master data entities can be simple or complex. Simple entities may have one or two attributes, whereas a complex entity may have other entities as attributes. An example of a simple entity in a patient management system can be a contact email address or phone number. An example of a complex entity is a patient having a name, address, email, and phone number as attributes.
Internally, the master data build process follows these steps for each entity type configured for master data generation:
1. Binning entities based on a selected subset of entity attributes using exact matches of raw or fuzzy versions of the attribute values.
2. Linking records within each bin.
3. A detailed scoring of entities in a bin based on closeness of attribute values using edit distance algorithms.
4. Grouping and filtering matches based on a given cutoff threshold (records in the same group are considered as belonging to the same entity).
5. Merging matching entities based on given merge rules to generate a master record for that entity.
This documentation serves as an example scenario for master data management and integration using sample data sources included in the EIQ Product Suite Installation media. The scenario is more focused on the healthcare perspective of master data management (MDM), but the processes and concepts discussed are very similar to the functionality of master data management in other organizational uses.
The main steps in the master data management guide are:
1. Build EIQ SuperAdapters for the data sources.
2. Configure data federation across the adapters.
3. Configure master data matching and merge rules to build master data.
4. Map master data columns for querying and execute sample queries.

Before building the EIQ Adapters, you need to set up the data sources and attach them to SQL Server.
The sample master data sources included in the EIQ Product Suite Installation media are referred to as PM and WORKS. Like the POLICE, FBI and INS data sources used throughout the rest of the EIQ Product Suite Help, these two sources are SQL Server relational databases. Just like before, the SQL Server database files need to be attached to Microsoft SQL Server before they are available for use.
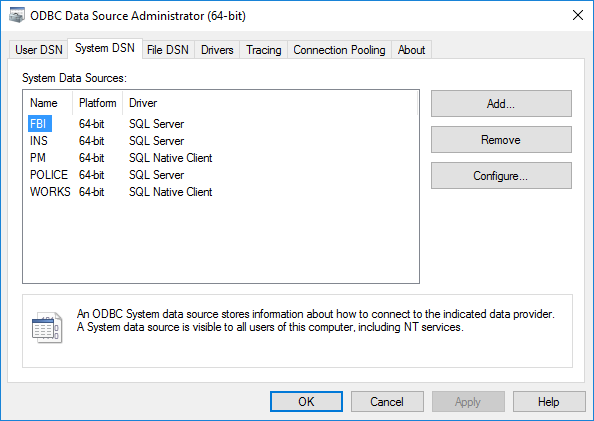
Before EIQ Products can access the master data sources, you need to create ODBC DSNs for the sample databases. Follow the steps provided below to create DSNs for PM and WORKS.
· Open ‘Administrative Tools’ from the Control Panel and then ‘ODBC Data Sources (64-bit)’.
· In the ‘System DSN’ tab, click ‘Add…’ to create a new data source.
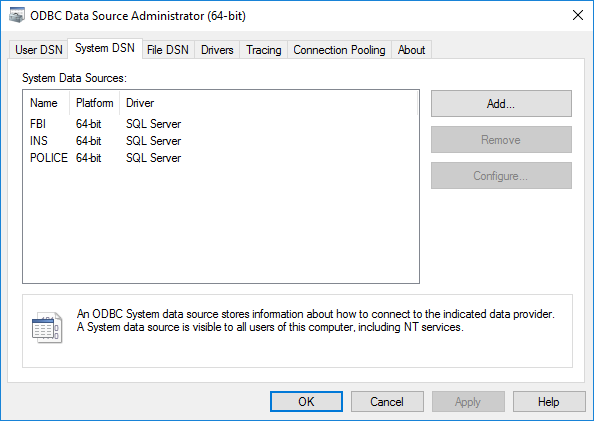
· The ‘Create New Data Source’ window opens.
· If you are using SQL Server 2000, select ‘SQL Server’ as the ODBC driver. For SQL Server 2005, select ‘SQL Native Client’. For SQL Server 2008, select ‘SQL Server Native Client 10.0’.
· Click ‘Finish’.
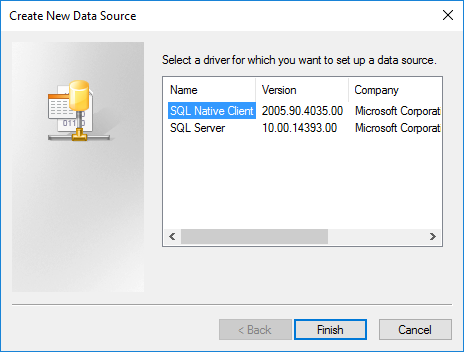
· The ‘Create a New Data Source to SQL Server’ window opens. Here, you will need to enter the appropriate information for the data source.
· Enter ‘PM’ for the name. The description field is optional.
· Select the server. If it is a local system, select ‘(local)’ and click ‘Next’.
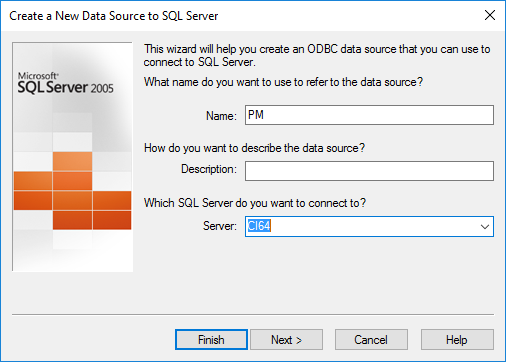
· Select the method of authentication for SQL server and click ‘Next’.
· The example uses SQL Server authentication.
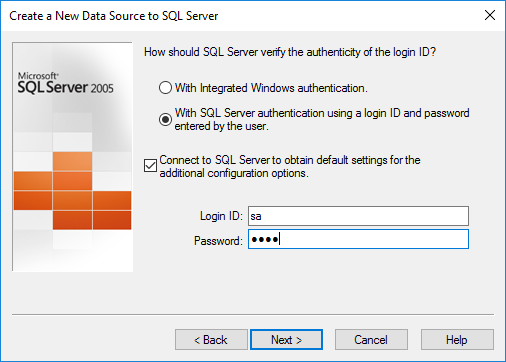
· Select ‘Change default database to’.
· Change the default database from ‘master’ to ‘PM_New’.
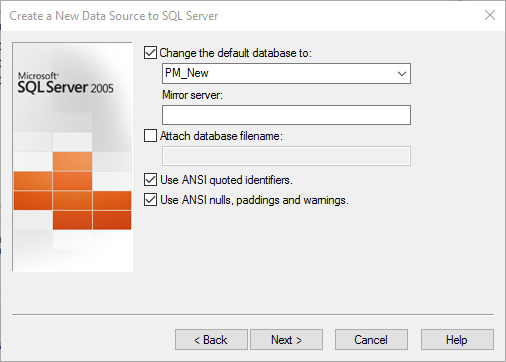
· Don’t select or deselect anything in the next window. Click ‘Finish’.
· Test the data source and click ‘OK’.
· Click ‘OK’ again.
Creating a DSN for WORKS is identical to the process for the PM database.
Once the ‘Create a New Data Source to SQL Server’ window opens,
· Enter ‘WORKS’ for the name.
· Select the server. If it is a local system, select ‘(local)’ and click ‘Next’.
· Select the method of authentication for SQL Server and click ‘Next’.
· Select ‘Change the default database to’ and change the name to ‘WORKS_New’. Click ‘Next’.
· Don’t select or deselect anything in the next window. Click ‘Finish’.
· Test the connection. Click ‘OK’ and click ‘OK’ again.
Now you should see the DSNs in the ‘System DSN’ tab. Click ‘OK’.
Now that the data sources have been set up, you need to configure EIQ SuperAdapters on them. Build the initial EIQ Indexes, link the indexes together using Link Indexing, create a SuperSchema mapping, and point them towards an EIQ Federation Server.
The first thing you need to do is build the initial EIQ Indexes for both of the master data sources. Start with the PM data source.
· Open the RTI Tool and select ‘Create a new EIQ Index RTI map’.
· Connect to the PM database and enter the authentication details.
· Specify the EIQ Index path and give the EIQ Index a name.
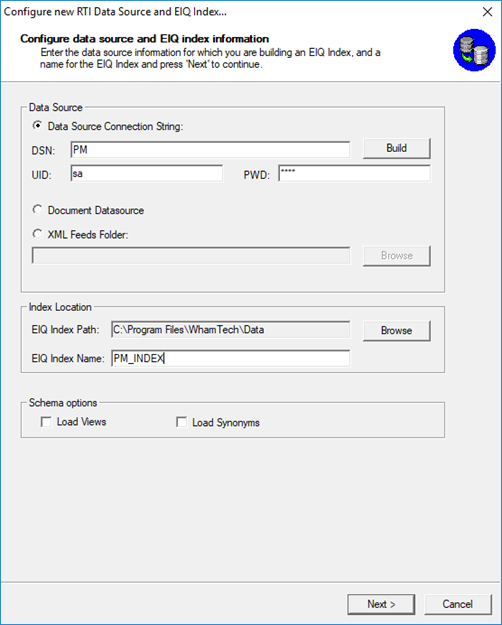
You can leave the global data type map as its default.
· Click ‘Finish’.
The new session begins in ‘Profiling’ mode.
· Expand ‘dbo’ in the left pane. This displays all of the tables available for indexing.
· Right-click the tables and select ‘Add all’ to move all of the columns in that table into the right pane.
· Otherwise, expand the table nodes and double-click the desired columns to add them.
· Add all of the desired tables and columns needed for the master data.

This demonstration uses the following tables and columns:
|
dbo.ADDRESSES · ADDRESS_ID · STREET1 · STREET2 · CITY · STATE · ZIP_CODE · PHONE · TimeSTMP · ADDRESS_CR (Derived Column) |
dbo.CONTACTS · CONTACT_ID · Account_ID · Is_Guarantor · FIRST_NAME · LAST_NAME · SSN · DATE_OF_BIRTH · EMAIL_ADDRESS · Employer_ID · CELL_PHONE · ADDRESS_ID · TimeSTMP · FIRST_NAME_MP (Derived Column) · LAST_NAME_MP (Derived Column) ·
EMAIL_CR |
dbo.Vouchers · Patient_ID · Account_ID · Actual_Prov_Practitioner_ID · Voucher_ID · Carrier_ID · Update_Status · Fees · Posted_Payments · Posted_Adjustments · Posted_Refunds · Posted_Misc_Debits |
dbo.Accounts · Account_ID · Account_Number |
|
dbo.Appointments · Patient_ID · Appointment_ID · Appointment_DateTime · Ref_Dr_Practitioner_ID · Appointment_Type_ID |
dbo.Appointment_Types · Appointment_Type_ID
|
dbo.Carriers · Carrier_ID · Insurance_Category_ID · POLICY_ID |
dbo.Diagnosis_Codes · Diagnosis_Code_ID · Diagnosis_Category_ID |
|
dbo.Employers · Employer_ID |
dbo.Insurance_Categories · Insurance_Category_ID |
dbo.Patient_Policies · Patient_Policy_ID · Patient_ID · Policy_ID |
dbo.Patients · Patient_ID · Account_ID · Relation_To_Guarantor · PCP_Practitioner · Contact_ID |
|
dbo.Policies · Policy_ID · Contact_ID · Effective_Date |
dbo.Practitioners · Practitioner_ID |
dbo.Service_Diagnoses · Service_Diagnosis_ID · Service_ID · Diagnosis_Code_ID |
dbo.Services · Service_ID · Voucher_ID |
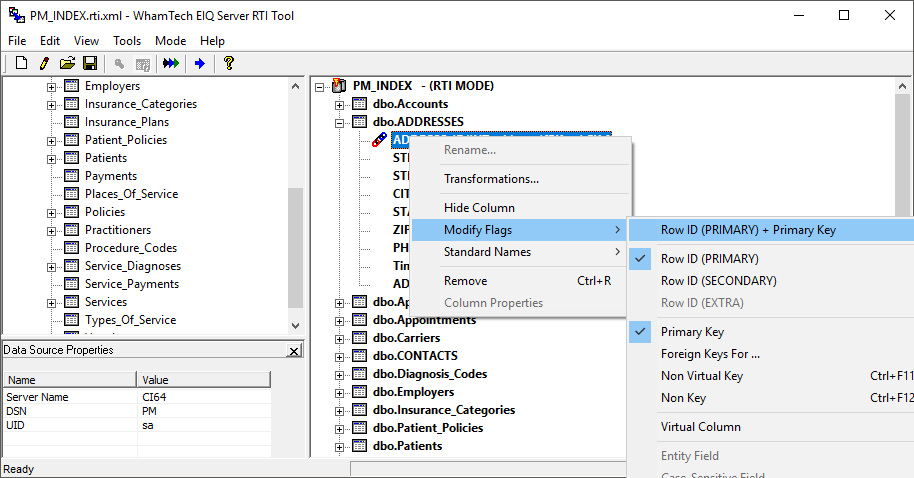
Now you can switch to RTI mode. When it prompts you to save, save the RTI map. Once you’re in RTI mode, you will need to set ROWIDs for every table in the index. The RTI tool will not build an EIQ Index if tables do not have ROWIDs. Right-click the desired columns and go to ‘Modify Flags’. Either select ROWID (Primary) or ROWID (Primary) + Primary Key. In order to link important tables properly, you’ll need to specify the following:
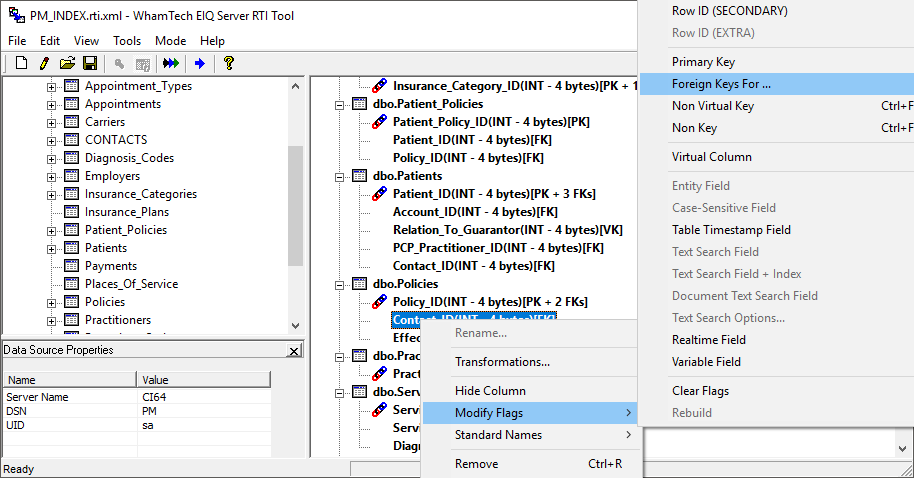
Now is a good time to apply transforms if you haven’t already done so. This demonstration uses derived columns to store table transforms like combining phone number columns, correcting addresses, and generating metaphone from name columns. Right-click a table node to apply a table transform or create a derived column.
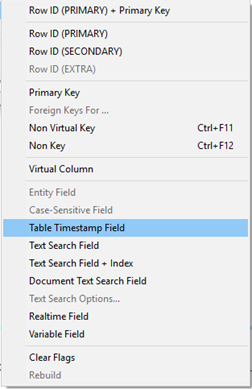
Before proceeding further, you need to modify the Timestamp (Date-Time or Date) columns in the RTI map. This is used to identify the most recent records for creating master data. There should be one in the ADDRESS table and one in the CONTACTS table.
· Right-click the column.
· Select 'Modify Falgs'.
· Click 'Table Timestamp Field'.
Don’t forget to specify text search fields. Columns called ‘Descriptions’ or ‘Comments’ should be designated as text search fields to allow queries to find key words in the columns. There should be 10 columns total throughout the indexed tables. Right-click the PM_INDEX node and select ‘Text Search Options’ to specify the parameters for text searching.
Once ROWIDs have been specified, Timestamp fields have been modified, and text search fields have been specified, you can build the EIQ Index for the PM data source. Click ‘Build EIQ Index’ on the toolbar and select ‘Full Build’. Save the RTI map and click ‘File’ and select ‘Close map’.
Now build the index for the WORKS data source. Click ‘File’ and select ‘New’.
· Connect to the WORKS database and enter the authentication details.
· Specify the EIQ Index path and give the EIQ Index a name.
· You can leave the global data type map as its default. Click ‘Finish’.
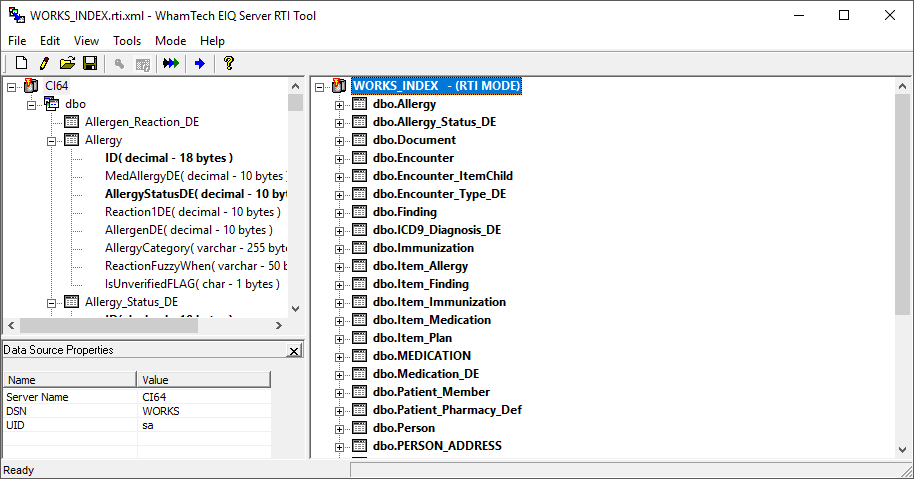
Like with the PM data source, index the tables and columns need to create the master data. This demonstration uses the following tables and columns.
|
dbo.Allergy · ID · AllergyStatusDE |
dbo.Allergy_Status_DE · ID |
dbo.Document · DocumentID · PatientID · EncounterID · EIEID · NextVersionID |
dbo.Encounter · ID · PatientID · EncounterType · DTTM |
dbo.Encounter_ItemChild · EncounterID · ItemID · ItemChildID · ItemType |
dbo.Encounter_Type_DE · ID · EntryName |
|
dbo.Finding · ID · NumericFinding · PerformedDTTM |
dbo.ICD9_Diagnosis_DE · ID · EntryCode · EntryName |
dbo.Immunization · ID · MedDictDE · AdministeredFuzzySortAs |
dbo.Item_Allergy · ID · CurrentID · PatientID |
dbo.Item_Finding · ID · PatientID · CurrentID · ItemType · EntryName · CreateDTTM · PerformedDTTM · DecodedValue |
dbo.Item_Immunization · ID · PatientID · CurrentID |
|
dbo.Item_Medication · ID · CurrentID · PatientID · CreateDTTM · EntryName |
dbo.Item_Plan · ID · PatientID · CurrentID · DetailType · LastUpdateDTTM · EntryName · CreateDTTM |
dbo.MEDICATION · ID · MedDictDE · StartFuzzySortAs · EndFuzzySortAs |
dbo.Medication_DE · ID · EntryName |
dbo.Patient_Member · ID |
dbo.Patient_Pharmacy_Def · PatientID · PharmacyID · PrescribeActionID |
|
dbo.Person · ID · LastName · FirstName · DateofBirth · SSN · TimeSTMP ·
Last_Name_MP ·
First_Name_MP |
dbo.PERSON_ADDRESS · ID · ADDRESSTYPE · ADDRESSLINE1 · ADDRESSLINE2 · CITY · STATE · ZIPCODE · TimeSTMP ·
ADDRESS_CR |
dbo.PERSON_OTHER · ID · EMAILADDRESS · TimeSTMP ·
EMAIL_CR |
dbo.PERSON_PHONE · ID · PHONETYPE · PHONEAREA · PHONEEXCHANGE · PHONELAST4 · TimeSTMP ·
PHONE |
dbo.Pharmacy_DE · ID · PhoneArea · PhoneExchange · PhoneLast4 · FaxArea · FaxExchange · FaxLast4 ·
Parmacy_Phone ·
Pharmacy_Fax |
dbo.Problem · ID · ProblemHeaderID · ProblemDE · ProblemTypeDE · ProblemStatusDE · ICD9DiagnosisDE · Problem · OnsetFuzzyWhen · RecordedDTTM |
|
dbo.Plan_Item · ID |
dbo.PrescribeAction_DE · ID |
dbo.Problem_Category_DE · ID |
dbo.Problem_Header · ID · PatientID · ProblemCategoryDE · CurrentProblemID |
dbo.Problem_Status_DE · ID |
dbo.Problem_Type_DE · ID |
|
dbo.Vaccine_Category_DE · ID · EntryName |
dbo.Vaccine_Medication_Mapper · MedicationDE · VaccineCategoryDE |
|
|
|
|
Now switch from ‘Profiling’ to RTI mode. When prompted to save, save the RTI map. Once you’re in RTI mode, you need to set ROWIDs for every table in the index, just like before. The RTI tool will not build an EIQ Index if tables do not have ROWIDs. Right-click the desired columns, go to ‘Modify Flags’ and select ROWID (Primary). Again, in order for tables to be properly linked, the tables need specific primary key and foreign key designations.
· Designate the ID columns or named ID column that matches the table name in each table as the ROWID (Primary) + Primary Key.
o Ex: ID in dbo.PERSON_PHONE is the ROWID (Primary) + Primary Key.
o Ex: DocumentID in dbo.Document is the ROWID (Primary) + Primary Key.
o There are a few exceptions:
§ ItemID in dbo.Encounter_ItemChild is the ROWID (Primary) + Primary Key. ItemChildID is the ROWID (Secondary) and a Primary Key.
§ PatientID in dbo.Patient_Pharmacy_Def is the ROWID (Primary) + Primary Key. PharmacyID is the ROWID (Secondary) and a Primary Key.
§ ID in dbo.PERSON_ADDRESS is the ROWID (Primary) + Primary Key. ADDRESSTYPE is the ROWID (Secondary) and a Primary Key.
§ ID in dbo.PERSON_PHONE is the ROWID (Primary) + Primary Key. PHONETYPE is the ROWID (Secondary) and a Primary Key.
§
MedicationDE in dbo.Vaccine_Medication_Mapper is
the ROWID (Primary) + Primary Key. VaccineCategoryDE
is the ROWID (Secondary) and a Primary Key.
· Designate the named columns that match other tables as Foreign Keys for the matching Primary Keys. Primary Keys can be Foreign Keys for other columns.
o Ex: EncounterID in dbo.Document is a Foreign Key for EncounterID in dbo.Encounter.
o Ex. PharmacyID in dbo.Patient_Pharmacy_Def is a Foreign Key for ID in dbo.Pharmacy_DE.
o There are some special cases:
§ ID in dbo.Patient_Member and ID in dbo.Person have a lot of Foreign Keys.
· Foreign Keys for ID in dbo.Patient_Member are dbo.Document.PatientID, dbo.Item_Allergy.PatientID, dbo.Item_Finding.PatientID, dbo.Item_Immunization.PatientID, dbo.Item_Medication.PatientID, dbo.Item_Plan.PatientID, and dbo.Patient_Pharmacy_Def.PatientID.
· Foreign Keys for ID in dbo.Person are dbo.Encounter.PatientID, dbo.Item_Medication.PatientID, dbo.Patient_Member.ID, dbo.PERSON_ADDRESS.ID, dbo.PERSON_OTHER.ID, dbo.PERSON_PHONE.ID, and dbo.Problem_Header.PatientID.
§ The CurrentID columns are Foreign Keys to the ID columns in the respectively named tables.
· Ex: CurrentID in dbo.Item_Allergy is a Foreign Key for ID in dbo.Allergy.
§ ItemID and ItemChildID in dbo.Encounter_ItemChild are Foreign Keys for ID in dbo.Plan_Item.
Again, don’t forget to apply the necessary transforms. This demonstration uses derived columns to store table transforms like generating metaphone for names, correcting addresses, and combining columns to create full phone numbers.
Next, modify the Timestamp (Date-Time or Date) columns in the RTI map. This will be used to identify the most recent records for creating master data. The important tables here are Person, PERSON_ADDRESS, PERSON_OTHER and PERSON_PHONE. Also, make sure to set the Problem column in the Problem table as a text search field and specify the parameters for text search indexing.
Once all of that is done, you can build the index. Click ‘Build EIQ Index’ on the toolbar and select ‘Full Build’.
After the indexes are built, you need to register the data sources with the EIQ Server Configuration Tool and create virtual data sources with virtual schema views (SuperSchema) for the EIQ SuperAdapters. Open the EIQ Server Configuration Tool and go to the ‘Data Sources’ tab.
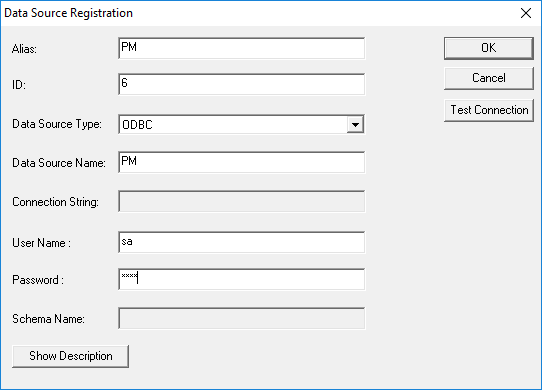
· Click ‘Add Data Source’.
· Enter ‘PM’ as the Alias.
· Enter an ID different than the other registered data sources’.
· Select ODBC as the data source type.
· Enter ‘PM’ as the data source name.
· Enter the username and password for the data source.
Now go to the ‘EIQ Server Virtual Data Sources’ tab to create a virtual data source.
· Click ‘Define New’.
· Enter the name ‘PM_VDS’
· Click ‘Add’ next to the ‘Data Source – EIQ Index Pairs’ box.
· Select ‘PM’ from the drop-down menu.
· Use ‘Browse’ to find the PM_INDEX.DBD file.
· Click ‘OK’ and then click ‘OK’ again.
· PM_VDS now appears in the list of virtual data sources.
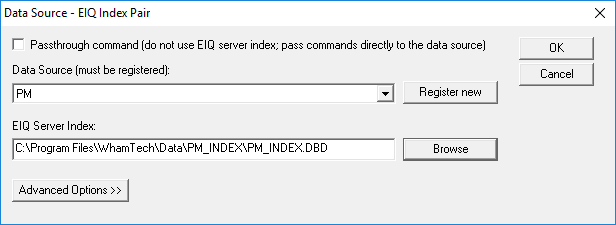
· Click ‘Add Data Source’.
· Enter ‘WORKS’ as the Alias.
· Enter an ID different than the other registered data sources’.
· Select ODBC as the data source type.
· Enter ‘WORKS’ as the data source name.
· Enter the username and password for the data source.
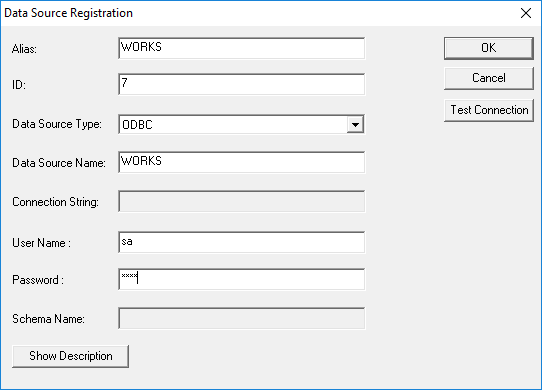
Now go to the ‘EIQ Server Virtual Data Sources’ tab to create a virtual data source.
· Click ‘Define New’.
· Enter the name ‘WORKS_VDS’
· Click ‘Add’ next to the ‘Data Source – EIQ Index Pairs’ box.
· Select ‘WORKS’ from the drop-down menu.
· Use ‘Browse’ to find the WORKS_INDEX.DBD file.
· Click ‘OK’ and then click ‘OK’ again.
· WORKS_VDS now appears in the list of virtual data sources.
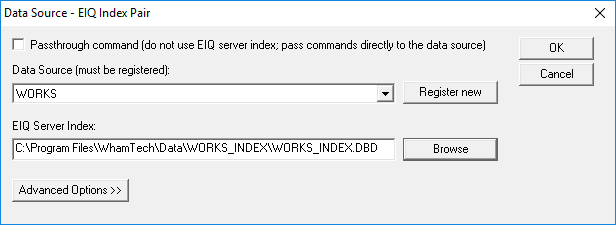
After a VDSs have been created for both data sources, you need to map them to a standard data model using the ‘SuperSchema Mapping’ tab. First, map the PM_VDS. Expand the PM_VDS node in the left pane of the ‘SuperSchema Mapping’ tab and click on the grey node. Find the columns below and map them to the example virtual schema view. These are the necessary tables and columns for the master data generation demonstration. Typically, all columns should be mapped to a standard data model.
Data Source Table Data Source Column Standard Data Model Column
ADDRESSES CITY CITY
ADDRESSES STATE STATE
ADDRESSES STREET1 STREET1
ADDRESSES STREET2 STREET2
ADDRESSES ZIP_CODE ZIP
CONTACTS DATE_OF_BIRTH DOB
CONTACTS LAST_NAME FAMILY_NAME
CONTACTS FIRST_NAME FIRST_NAME
CONTACTS EMAIL_ADDRESS EMAILID
CONTACTS PHONE PHONE
CONTACTS SSN SSN
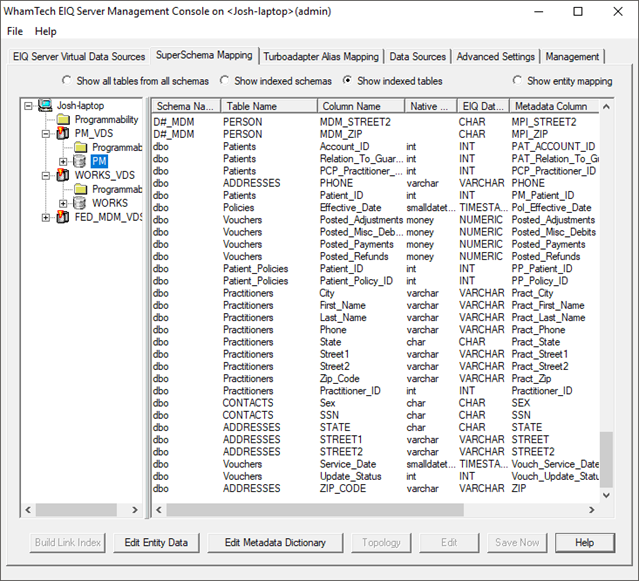
A general SuperSchema mapping for the PM_VDS should look like the screenshot below.
Now you need to map the WORKS_VDS. Expand the WORKS_VDS and click the grey node. Find the columns below and map them to the example standard data model.
Table Name Data Source Name Standard Data Model Name
PERSON_ADDRESS CITY CITY
PERSON_ADDRESS STATE STATE
PERSON_ADDRESS ADDRESSLINE1 STREET1
PERSON_ADDRESS ADDRESSLINE2 STREET2
PERSON_ADDRESS ZIPCODE ZIP
Person DateofBirth DOB
Person LastName FAMILY_NAME
Person FirstName FIRST_NAME
Person SSN SSN
PERSON_PHONE PHONETYPE PHONE
PERSON_OTHER EMAILADDRESS EMAILID
ICD9_Diagnosis_DE EntryCode DIAGNOSIS_CODE
ICD9_Diagnosis_DE EntryName DIAGNOSIS_DESCRIPTION
Item_Plan EntryName IP_OrderName
Item_Plan CreateDTTM IP_ORDER_Date
Item_Medication EntryName MEDICATION
Item_Medication CreateDTTM MEDICATION_ORDER_Date
Problem Problem PROB_PROBLEM
Problem RecordedDTTM PROBLEM_Date
A general SuperSchema mapping for the WORKS_VDS should look like the screenshot below.
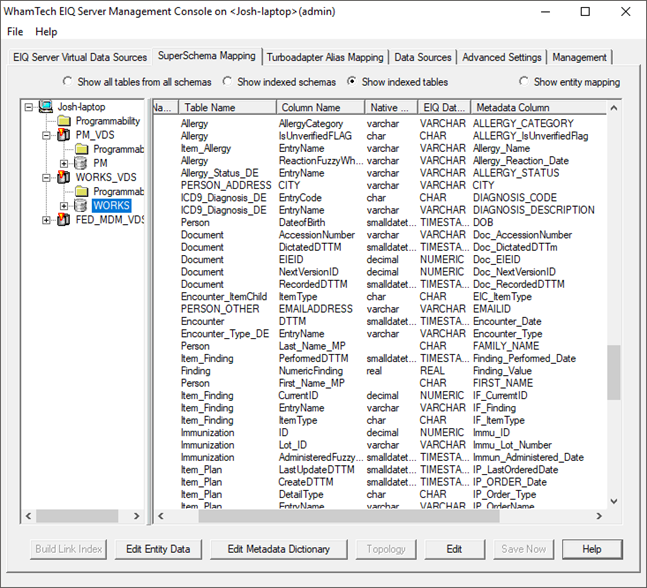
Now that the VDSs have a SuperSchema mapping, create the EIQ Federation Server that the EIQ SuperAdapters will point to.
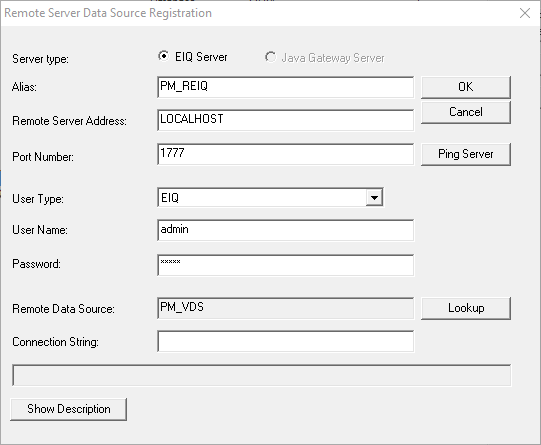
Go back to the ‘Data Sources’ tab. You need to create remote server data sources for PM and WORKS.
· Enter the alias ‘PM_REIQ’
· Enter the address of the remote server. If it is local, then enter ‘LOCALHOST’.
· Specify the port number.
· Select the user type and enter the login credentials.
· Click ‘Lookup’ and select the PM_VDS.
· Click ‘OK’.
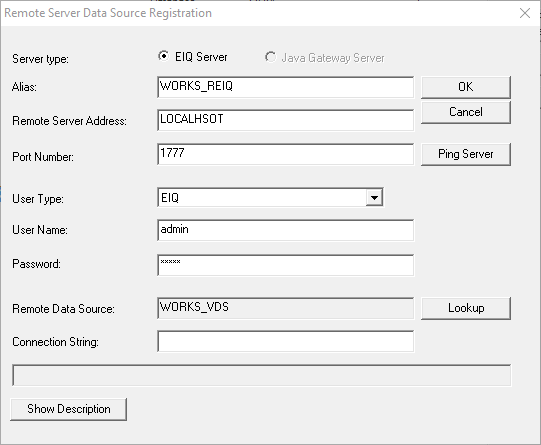
· Enter the alias ‘WORKS_REIQ’
· Enter the address of the remote server. If it is local, then enter ‘LOCALHOST’.
· Specify the port number.
· Select the user type and enter the login credentials.
· Click ‘Lookup’ and select the WORKS_VDS.
· Click ‘OK’.
You should now see both PM_REIQ and WORKS_REIQ added to the list of data sources. Go to the ‘EIQ Server Virtual Data Sources’ tab to finish creating the EIQ Federation Server.
· Click ‘Define New’.
· Enter the name ‘FED_MDM_VDS’.
· Click ‘Add’ next to the ‘Data Source – EIQ Index Pairs’ box.
· Select ‘PM_REIQ’ from the drop-down menu and click ‘OK’.
· Repeat the last two steps for the ‘WORKS_REIQ’.
· Click ‘OK’.
You should now see FED_MDM_VDS added to the list of Virtual Data Sources.
In order to create a proper Link Index for the master data, you need to make sure the entity data is accurate and has all of the fields you need. This helps create link indexes with all the necessary data.
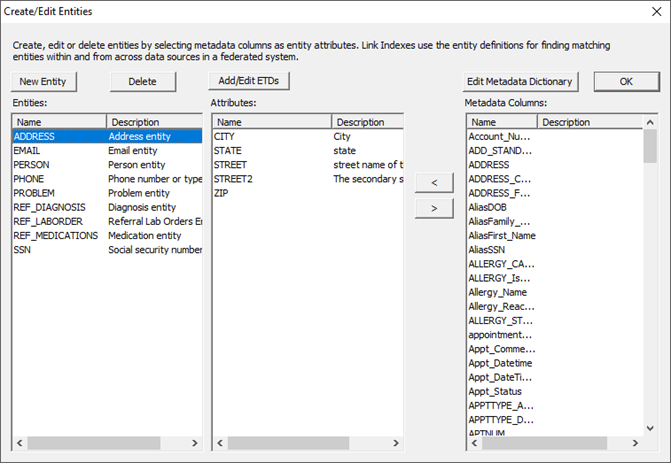
Go to the ‘SuperSchema Mapping’ tab and click ‘Edit Entity Data’ at the bottom of the window. To define an entity, you need to make sure that the attributes that define a unique field are all in the center pane under the proper entity. For example, if the combination of the FAMILY_NAME, FIRST_NAME and DOB fields define a unique PERSON entity, those three fields become attributes for the PERSON entity and should be added to the center pane.
The following table contains the entities you have, or need to add, and the attributes that populate those entities.
|
Entity Name |
Attributes |
|
PERSON |
FAMILY_NAME, FIRST_NAME, DOB |
|
ADDRESS |
CITY, STATE, STREET1, STREET2, ZIP |
|
|
EMAILID |
|
PHONE |
PHONE |
|
SSN |
SSN |
|
PROBLEM |
PROB_PROBLEM, PROBLEM_Date |
|
REF_DIAGNOSIS |
DIAGNOSIS_CODE, DIAGNOSIS_DSCRIPTION |
|
REF_MEDICATIONS |
MEDICATION, MEDICATION_ORDER_Date |
|
REF_LABORDER |
IP_OrderName, IP_ORDER_Date |
To create an entity, click ‘New Entity’. Enter a name for the entity and, if necessary, a description. Entities will auto-populate with one attribute when created. Using the ‘Metadata Columns’ box, search for the attributes that define the entity you created and add them to the ‘Attribute’ box by selecting them and clicking the left arrow. Remove any incorrect or unnecessary attributes by selecting them and clicking the right arrow.
With the EIQ SuperAdapters configured, the EIQ Federation Server created, and the entities defined, you can now create a Link Index for the master data. Go to the ‘SuperSchema Mapping’ tab.
· Expand the server node in the left pane and find FED_MDM_VDS.
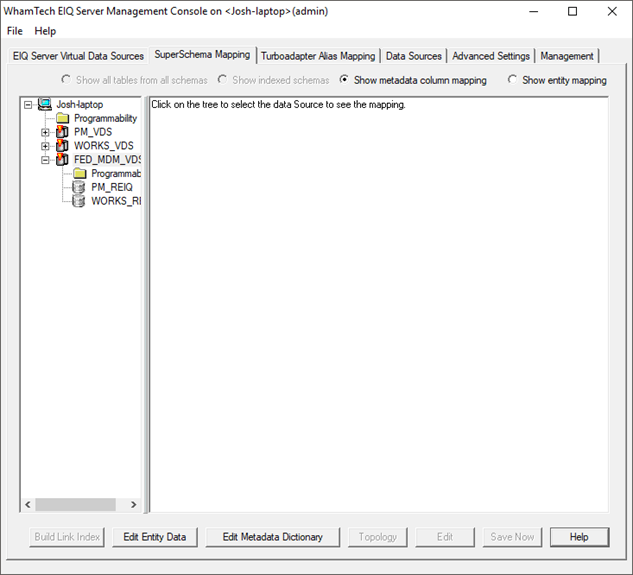
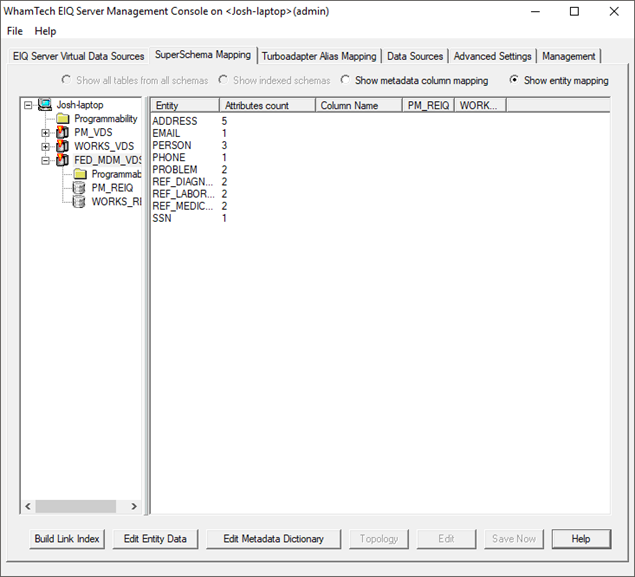
· Select ‘show entity mapping’ (below the advanced settings and management tabs).
This menu shows the entities defined, the number of attributes defining those entities, and the remote servers under the EIQ Federation Server.
· Click ‘Build Link Index’ in the bottom.
· This shows the available entities on the EIQ Federation Server. All matching rules are set to ‘Exact’ by default.
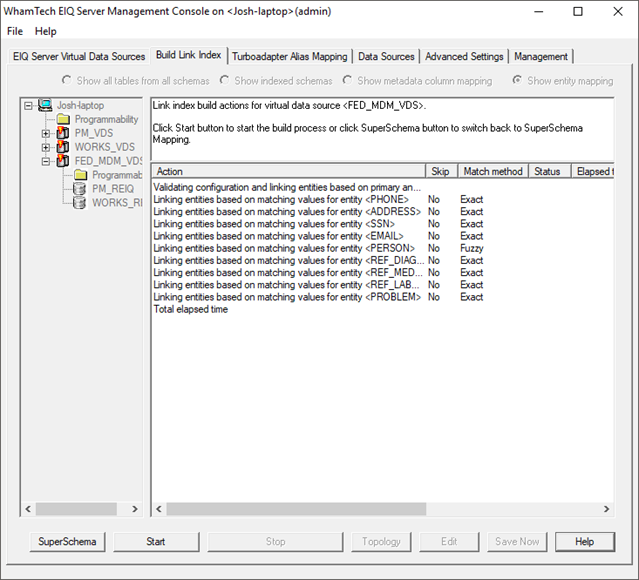
You may need to apply fuzzy matching to certain fields. Fuzzy matching is a technique that assists in record linkage. It works with matches that may be less than 100% perfect when finding correspondences between segments of a text and entries in a database of previous translations. Rather than having multiple files for one patient, use it to find similarities between data sources and match together patient records into one master patient index.
· Select the entity where you need to apply Fuzzy Matching, for example, the PERSON entity.
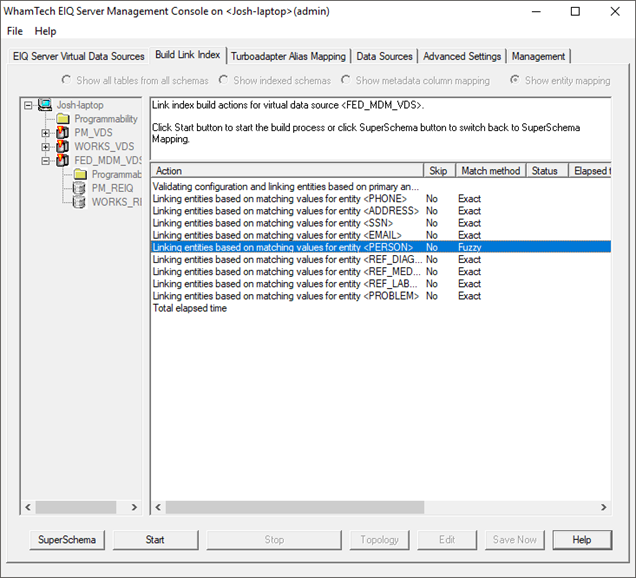
· Right-click on the Entity Name
· Select “Configure matching rule on ‘PERSON’”.
· The “Fuzzy match rule for ‘PERSON’” window will open.
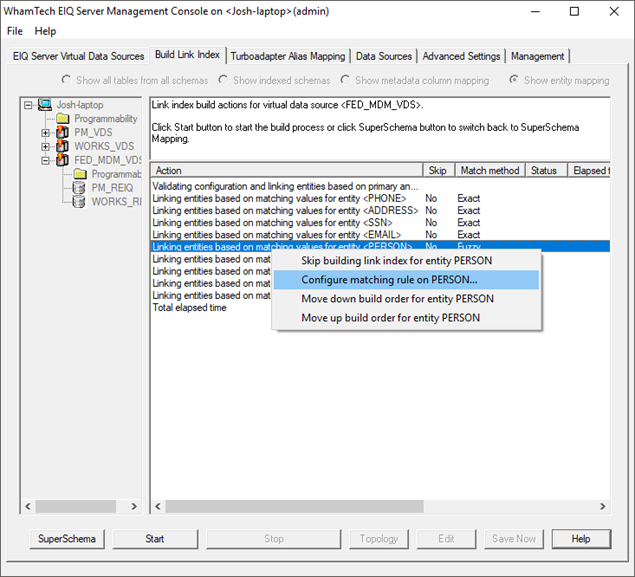
· Select “Fuzzy Match” in the ‘Select Option’ box.
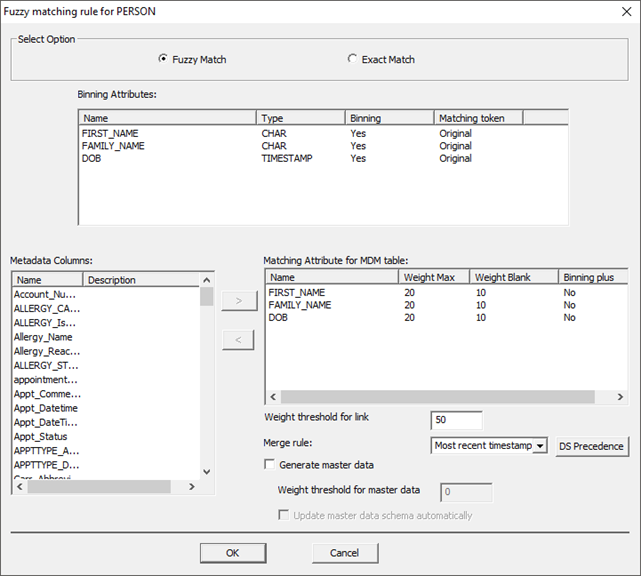
The tool automatically populates entity attributes as Binning Attributes. Now, select the Binning Attributes and modify them as per requirements. For example:
· Set “Matching Token” for FIRST_NAME as Metaphone.
· Set “Matching Token” for LAST_NAME as Metaphone.
· Set “Matching Token” for DOB as Original.
Double-click ‘Original’ to activate the drop-down menu and select the proper token. This tells the system to use metaphone (sound) to bin the attributes, not the original value (e.g. Stephanie and Steffanie will be grouped together).
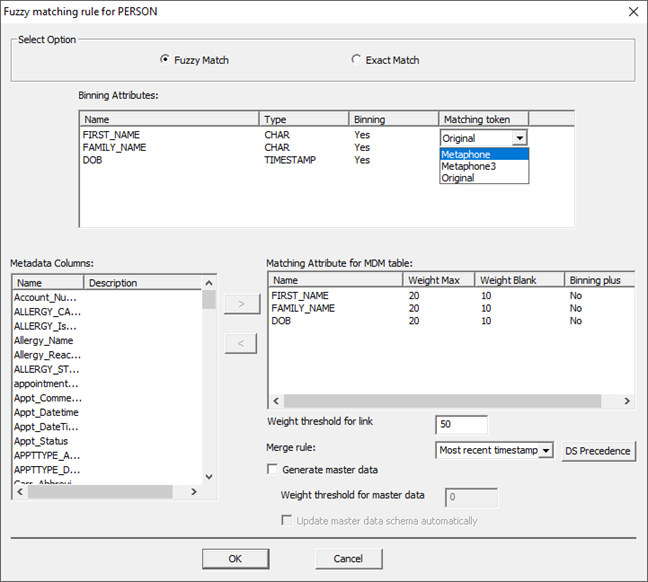
· Add the Matching Attributes for the MDM Table. This should be all the columns in your master data set you want to merge like CITY, SSN, PHONE, and etc. Add them by selecting them in the ‘Metadata Columns’ box and clicking the left arrow. To remove an attribute, select it in the ‘Matching Attribute for MDM table’ box and click the right arrow.
· Add Weight Max for each attribute and Weight Blank as per the requirement.
· Add Weight Threshold for link. (This is the threshold required for a link to be created between the records).
· Select “Generate master Data”.
o Update the Weight Threshold for master data accordingly. (This is the minimum total weight required for a record to be merged).
o This uses the raw value not a percentage.
o Merge rule: Most recent timestamp -- Tells it to get the most recent record when merging records for MDM.
o Max Weight is the maximum value possible for that attribute, exact match gets the full weight and fuzzy logic gets a fraction based on the calculated distance.
· Select “Update master data schema automatically”.
o It automatically updates the schema if new attributes are added after initial creation.
· Click “OK”
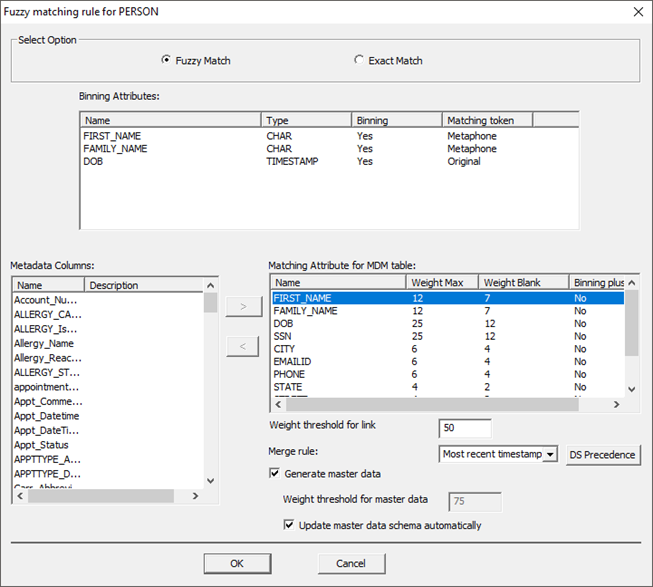
· Click ‘Start’ to build the index.
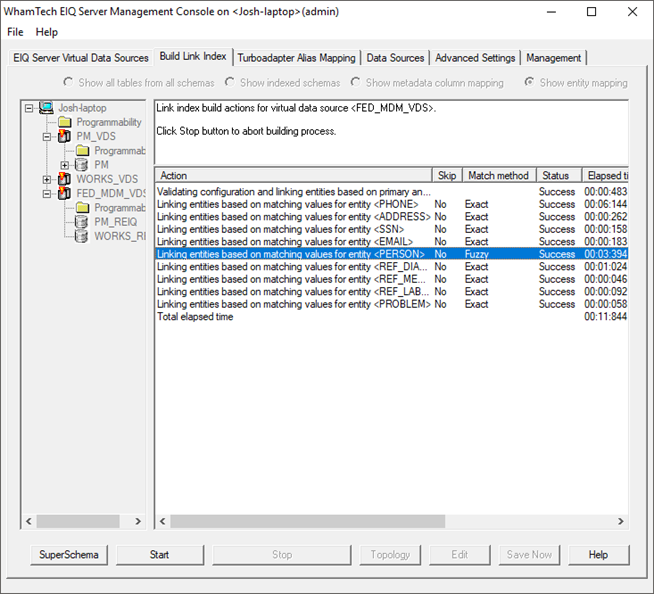
Now that the index has been built successfully, the FED_MDM_VDS needs a SuperSchema mapping.
· Click ‘SuperSchema’ in the bottom-left to return to the mapping screen.
· Go to the WORKS_VDS or PM_VDS, expand the tree, and click on the grey node.
· Make sure ‘show indexed tables’ is selected.
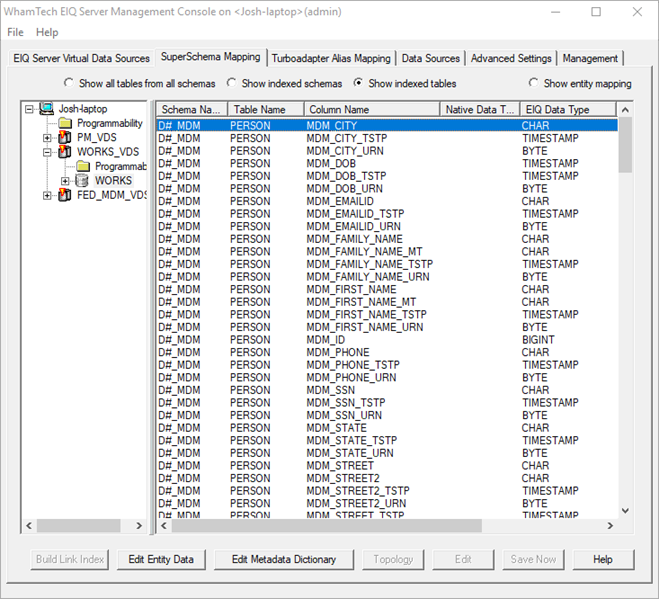
The “D#_MDM” schema has been added and a PERSON table has been created with the selected matching attributes. Building the Link Index has created an entirely new schema and table for the master data. The same schema and table are available in both the PM_VDS and WORKS_VDS. In real use scenarios, every VDS that was connected to the EIQ Federation Server with the same entities when the Link Index was built will have the new Master Data schema and table. The Link Index build has created the master data for the users.
Now users can add Metadata Column Names to their master data columns to give it a virtual schema view. Follow the procedure below to add Metadata Column Names:
· Select Column MDM_CITY -> right-click and select ‘Edit’.
· The SuperSchema Column Definition window opens.
· Now enter the Metadata Column Name: “MPI_CITY”. MPI is used to specify that it is the Master Patient Index.
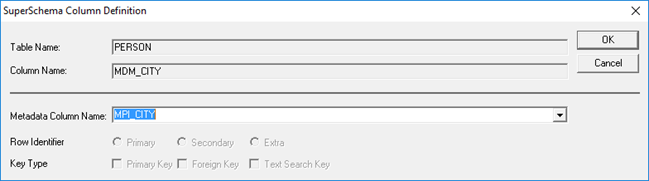
· Do this for all of the columns listed below as well.
Virtual Data Source Column Standard Data Model Column
MDM_CITY MPI_CITY
MDM_STATE MPI_STATE
MDM_STREET MPI_STREET
MDM_STREET2 MPI_STREET2
MDM_ZIP MPI_ZIP
MDM_DOB MPI_DOB
MDM_FAMILY_NAME MPI_FAMILY_NAME
MDM_FIRST_NAME MPI_FIRST_NAME
MDM_EMAILID MPI_EMAILID
MDM_ID MPI_MDM_ID
MDM_PHONE MPI_PHONENUMBER
MDM_SSN MPI_SSN
· Click “Save Now” to save the SuperSchema mapping.
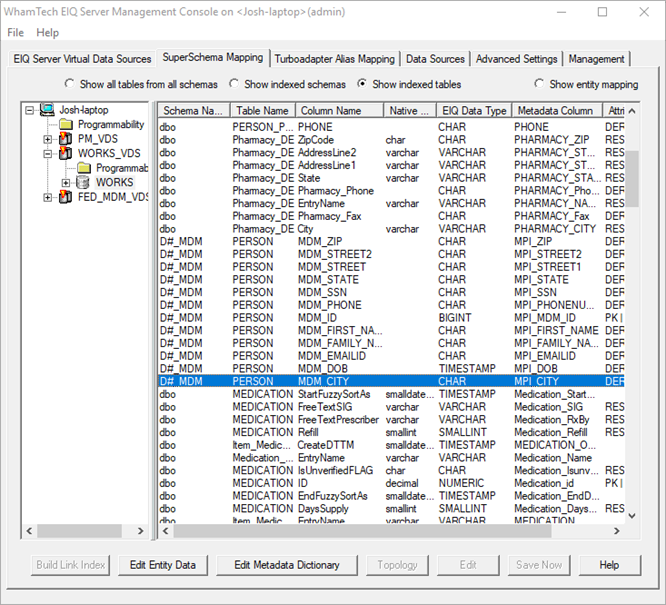
This completes the MDM setup and creation process. Using the EIQ Server Query tool, connect to the EIQ Federation Server and make queries as usual.
To query on the master data, connect to the EIQ Federation Server where the Link Index and master data table were created. Open the EIQ Server Query Tool and connect to the FED_MDM_VDS.
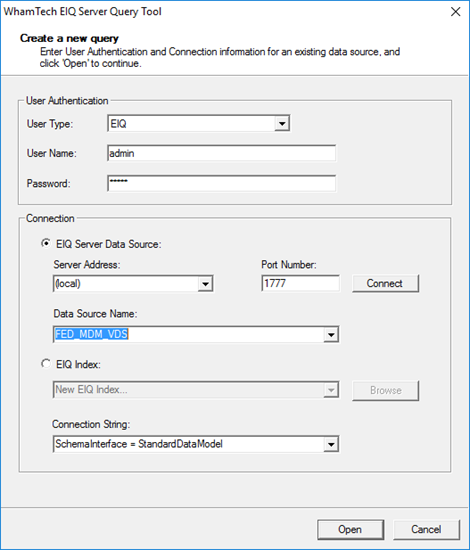
Try the sample query SELECT * FROM mytable.
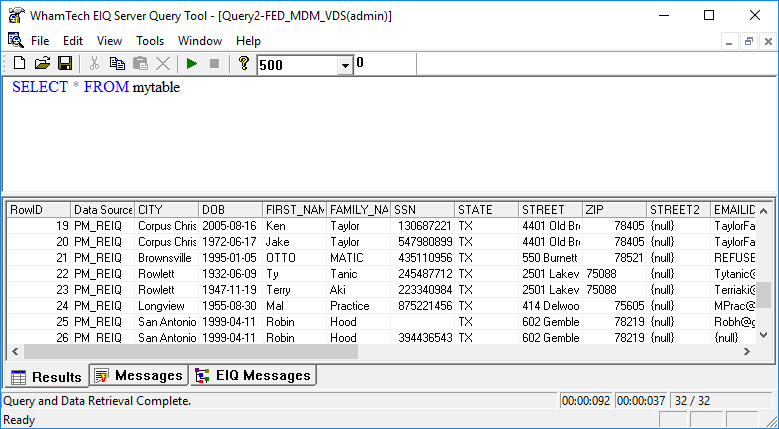
This query shows all of the columns mapped to the standard data model. Users can see the original columns from the PM and WORKS VDSs and the master data created using Link Indexes. Users should also be able to see some of the differences. For example, try the query SELECT * FROM mytable WHERE family_name = ‘Burley’.
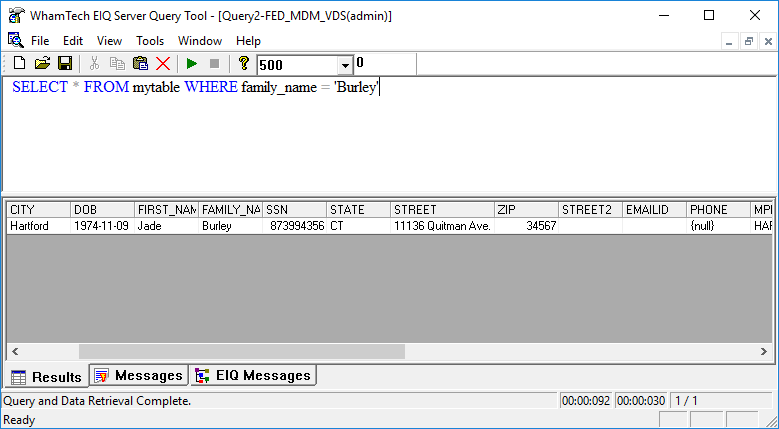
The information in the PM_VDS has found a ‘Jade Burley’ that lives in Hartford, CT at 11136 Quitman Ave. When users look at the master data, they find new results.
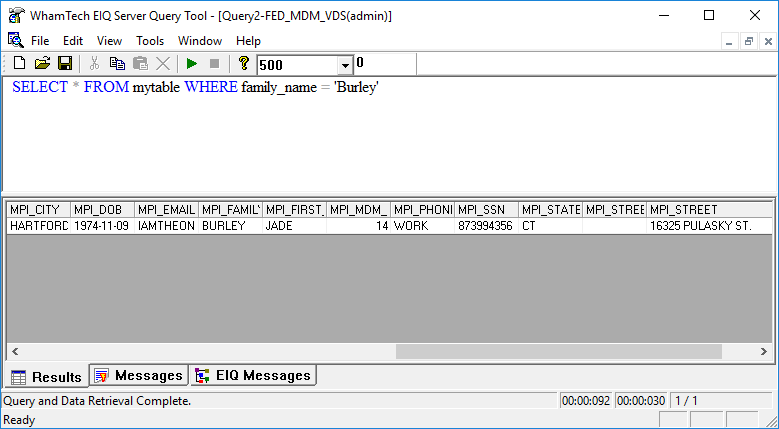
The master data has found the same ‘Jade Burley’ with the same Date of Birth, Social Security Number and State. That information tells users that it is, in fact, the same ‘Jade Burley’. The master data has also found a new street address, 16325 Pulasky St., in the same city and has also discovered an email address. Users can infer that ‘Jade Burley’ may have moved recently; information they may have never discovered without master data being created from the disparate sources. This is extremely vital when trying to keep patient or client information accurate and up-to-date.
Copyright © 2019 , WhamTech, Inc. All rights reserved. This
document is provided for information purposes only and the contents hereof are
subject to change without notice. Names may be
trademarks of their respective owners.